log(e^3 / d^2) / 4.5 = 1
where:
e is ELO difference
d is depth difference in %
As example for
3/2 326
e = 326
d = (3-2)*100/3 = 33%
log(326^3 / 33^2) / 4.5 = 1.00
log(e^3 / d^2) / 4.5 = 1
where:
e is ELO difference
d is depth difference in %
As example for
3/2 326
e = 326
d = (3-2)*100/3 = 33%
log(326^3 / 33^2) / 4.5 = 1.00
I did the fit with your formula, it fits very well with a single variable (4.5 in your case, which I left free for the fit). The correlation is 0.961355, and it is amazing for only one variable, my Pade fit involved 7 variables with 0.99 correlation. To 80th ply it got 26 Elo per ply, which is again close to previous numbers. We need more games, as two-sigma 55 Elo error bars are pretty large.
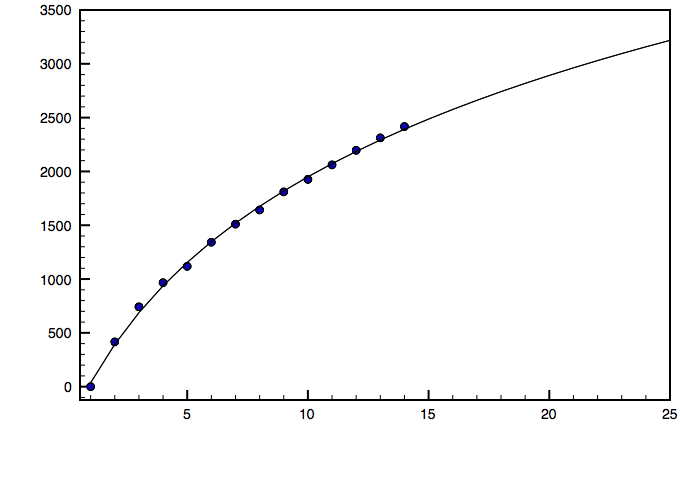
I calculated the aggregate elo at each depth, arbitrarily setting the strength at 1 ply to 0. The result certainly looks logarithmic to me, although this is hardly a rigorous test.
Aaron Becker wrote:I calculated the aggregate elo at each depth, arbitrarily setting the strength at 1 ply to 0. The result certainly looks logarithmic to me, although this is hardly a rigorous test.
For a long time (based on curve fitting of proportion of draws in human players as ELO rating increases), I have wondered whether 3500 (or thereabouts) is an upper limit in chess. It could be that above this level, a player simply becomes impossible to beat.
I would like to emphasise that while I obviously have no proof for this idea, I certainly do take it seriously.
Regarding diminishing returns of increasing search depth: unless the evaluation is unbelievably bad, then if it is possible to improve the play (in terms of avoiding turning wins into draws, or drawn positions into losses), then increasing search depth MUST eventually improve it.
Writing is the antidote to confusion.
It's not "how smart you are", it's "how are you smart".
Your brain doesn't work the way you want, so train it!
Aaron Becker wrote:I calculated the aggregate elo at each depth, arbitrarily setting the strength at 1 ply to 0. The result certainly looks logarithmic to me, although this is hardly a rigorous test.
I calculated the correlation based on differences between successive points, it is 0.940886, if I am not wrong (you meant log to base 10, right?). It might look logarithmic even if it is not, as for large x, log(x+1) - log(x) ~ 1/x + O(1/x^2), and in this case Pade approximants work better. The correlation is not too bad for only 4 parameters, I have 7 parameters to get 0.99 correlation with a Pade approximant. Interesting thing is that at the 80th ply the difference is about 20 points between successive plies, as in previous fits.
There's enough noise in the data that I would be concerned about overfitting by adding more parameters. For example, I'm not sure what phenomenon accounts for this part of the data:
4/3 224
5/4 152
6/5 224
but I wouldn't want to model it without understanding what's going on. In any case, I think ultimately the curve should not be logarithmic, because we should expect the strength gain with increasing search depth to trend to zero relatively quickly (certainly it should be zero well before depth 1000).
I don't really see any evidence for diminishing returns here. Considering the noise level the data is perfectly consistent with a linear Elo increase with depth, apart from the first 4 ply where it is steeper.
This different behavior at low depth is to be expected from the way we _know_ the search to work: Some search techniques that reduce the effective branching ration, in particular Late Move Reductions, become active only after a certain depth is reached. At 2 ply adding a ply really adds a ply to every branch. At 15 ply adding a ply does fail to extend many branches, that extra ply is quite "hollow". So of course you get less Elo from it than from a "solid" ply. At 3 ply you cannot even fully reduce the null move.
It really would be a miracle (and thus highly suspect) if the data at low depth could be fitted by the same formula as that at asymptotic depths.
Throw out the low data points and a linear fit doesn't look too bad. Whether the curve is linear, logarithmic, or something else, obviously there will be a point of diminishing returns eventually, because the game tree will bottom out. I just wonder how deep you have to go before it becomes impossible to gain significant strength. This is probably possible to actually figure out with games that have been solved, like checkers.
Aaron Becker wrote:I calculated the aggregate elo at each depth, arbitrarily setting the strength at 1 ply to 0. The result certainly looks logarithmic to me, although this is hardly a rigorous test.
For a long time (based on curve fitting of proportion of draws in human players as ELO rating increases), I have wondered whether 3500 (or thereabouts) is an upper limit in chess. It could be that above this level, a player simply becomes impossible to beat.
I would like to emphasise that while I obviously have no proof for this idea, I certainly do take it seriously.
Regarding diminishing returns of increasing search depth: unless the evaluation is unbelievably bad, then if it is possible to improve the play (in terms of avoiding turning wins into draws, or drawn positions into losses), then increasing search depth MUST eventually improve it.
I don't believe there is any real upper limit on rating for the time being. The initial rating of a program is arbitrary already. And so long as they continue to get stronger, they are going to continue to climb. Until we reach the point where a program can discover the game theoretic value from any starting position, it can always be drawn or beaten. Since programs are already at the 3,000 level or so on fast hardware, and since they still make lots of bonehead moves, there is at least another 1,000 rating points to be had and probably 2x to 3x that before we get to perfect play if that ever happens.
hgm wrote:I don't really see any evidence for diminishing returns here. Considering the noise level the data is perfectly consistent with a linear Elo increase with depth, apart from the first 4 ply where it is steeper.
This different behavior at low depth is to be expected from the way we _know_ the search to work: Some search techniques that reduce the effective branching ration, in particular Late Move Reductions, become active only after a certain depth is reached. At 2 ply adding a ply really adds a ply to every branch. At 15 ply adding a ply does fail to extend many branches, that extra ply is quite "hollow". So of course you get less Elo from it than from a "solid" ply. At 3 ply you cannot even fully reduce the null move.
It really would be a miracle (and thus highly suspect) if the data at low depth could be fitted by the same formula as that at asymptotic depths.
I tend to agree.
First, it seems intuitive that there _must_ be a diminishing return at some point, because once you play perfectly, additional depth will no longer improve the rating. But trying to extrapolate 40 ply search results from 20 ply current data is way too speculative to be convincing.
The curve probably varies from program to program as well. A pure material program will not get much from an additional ply until it can search deeply enough to see to the end of the game, while a program with lots of knowledge will play positionally accurately and increase tactically with additional depth.