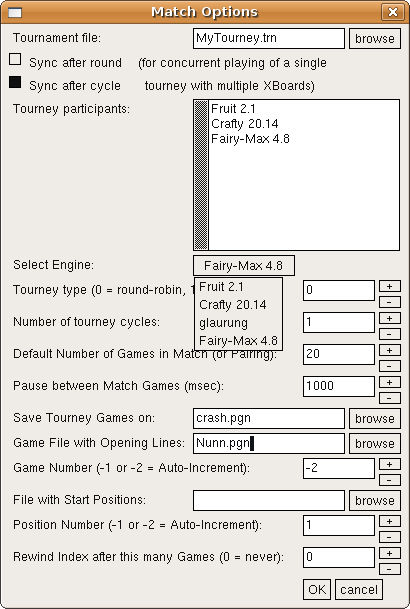
But reserving the space for all games, and indicating the unplayed games by spaces, is not a bad idea. So what I was thinking of is something like this:
Code: Select all
-processes "A C "
-participants {fruit
fairymax
glaurung
crafty
}
-tourneyType 0
-tourneyCycles 1
-gamesPerPairing 4
-loadGameFile "Nunn.pgn"
-loadGameIndex -2
-saveGameFile "RR1293.pgn"
-results "+=--++=+==-+-=A+C "
The -processes string reserves a single character position for each busy process; starting a new game process on the same tourney file would look in the string for the first un-assigned position (in this case B), take on that identity, (writing the B to reserve it), and grab the first space from the -results string (also marking it as B).
OTOH, having the length of the -result string not fixed could have some advantage as well. e.g. you could want to add another cycle to the tourney, perhaps with another -loadGameFile, and it would be good if you could do that by just editing the file to change the -tourneyCycles number, without having to count out spaces to add in the -result string (which might be hundreds...).