
Code: Select all
Key:
1) Lc0_LS15 d=1 (time: 100 ms scale: 5.0)
2) Lc0_LS15 t=500ms (time: 100 ms scale: 5.0)
3) SF_11 d=1 (time: 100 ms scale: 5.0)
4) SF_11 t=500ms (time: 100 ms scale: 5.0)
5) SF_12 d=1 (time: 100 ms scale: 5.0)
6) SF_12 t=500ms (time: 100 ms scale: 5.0)
1 2 3 4 5 6
1. ----- 80.35 30.80 52.55 48.90 60.50
2. 80.35 ----- 29.30 52.75 44.30 63.90
3. 30.80 29.30 ----- 33.35 30.30 28.05
4. 52.55 52.75 33.35 ----- 41.60 52.75
5. 48.90 44.30 30.30 41.60 ----- 44.45
6. 60.50 63.90 28.05 52.75 44.45 -----
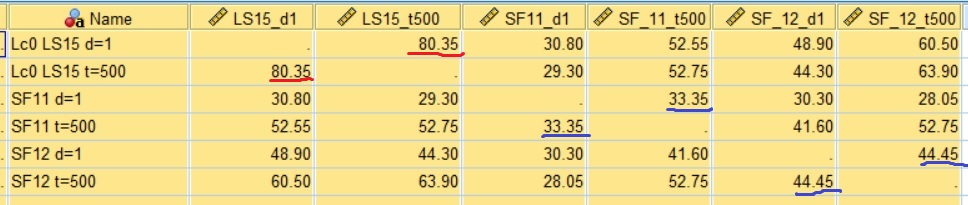
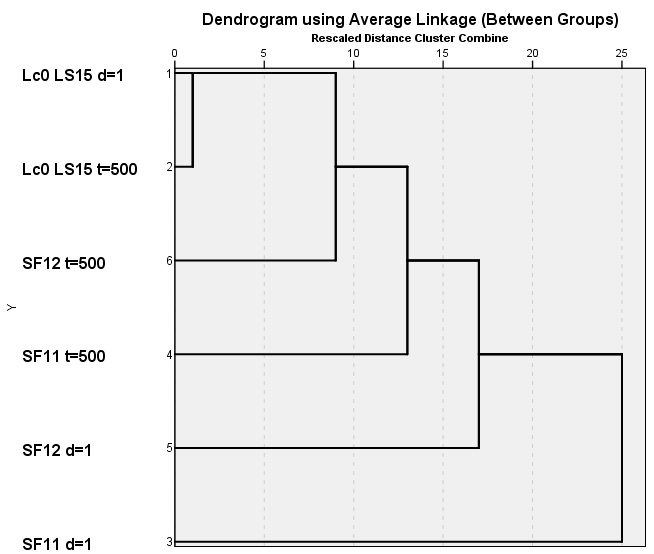
The 80% match between Leela policy (depth=1) and Leela=500ms is outstanding, and even more impressive compared to classical engine self-similarity in openings and NNUE engine self-similarity (underlined in blue). I checked self-similarity to longer 5s/move time control, and the self-similarity barely decreased from 80% to 77%. This is huge domination of policy over even a long evaluation in very visited during training, early good openings. I plotted the clustering diagram to show the Leela policy "attractor" to which all engines approach.
================================
================================
Second point I wanted to check was whether this domination is present only in openings used during the training (like the sound early opening positions I used here). I used Chess960 1-mover openings with the Sim tool to check for openings Leela never trained on, and the results were completely different:
Code: Select all
Key:
1) Lc0_LS15_500ms (time: 100 ms scale: 5.0)
2) Lc0_LS15_d1 (time: 100 ms scale: 5.0)
3) SF11_500ms (time: 100 ms scale: 5.0)
4) SF12_500ms (time: 100 ms scale: 5.0)
5) SF_11_d1 (time: 100 ms scale: 5.0)
6) SF_12_d1 (time: 100 ms scale: 5.0)
1 2 3 4 5 6
1. ----- 46.95 45.30 43.05 20.90 16.50
2. 46.95 ----- 41.30 36.40 24.95 17.65
3. 45.30 41.30 ----- 39.35 23.45 14.95
4. 43.05 36.40 39.35 ----- 23.25 21.55
5. 20.90 24.95 23.45 23.25 ----- 23.20
6. 16.50 17.65 14.95 21.55 23.20 -----
The more in line with the other two engines and with the common sense, Leela's match rate of 47% of policy versus eval at 500ms for Chess960 shows that for positions not trained on, the behavior is drastically different. Chess960 and regular Chess after several moves are basically the same game, so this difference in Leela policy behavior depending on training set is quite remarkable. Also, Leela depth=1 underperforms in Chess960 compared to regular chess by more than 100 Elo points against regular engines, so this policy tree building in the openings based on the training set is akin at least in strength to an opening book.