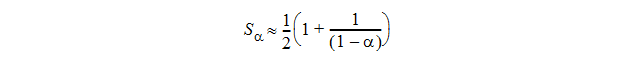syzygy wrote: ↑Mon Jun 04, 2018 12:53 am
I think the Robin Hood trick should leave the average exactly unchanged. (I am guessing that the double counting of symmetric tables somehow explains the change from 2.06 to 2.05.) Reducing the worst case length is probably a good thing.
FWIW, the supposed advantage is that moving a bunch of elements from 1 to 2 probes is likely to be fairly inconsequential, since the next element is likely to be already in the cache (either on the same cache line, or prefetched), so moving 60 such elements to get one element down from 68 to 8 is an overall win. I haven't measured myself, but it makes sense to me.
I agree the average should have stayed put. I think the reason why it doesn't is a minor bug in my counting, now that I think of it (I don't necessarily look in the overflow bucket).
syzygy wrote: ↑Mon Jun 04, 2018 1:10 am
According to this page, the average number of probes for successful find is estimated to be
For alpha = 3002/4096, this gives 2.372. So what you measured is better than expected.
For alpha = 3002/8192, we get 1.289, which is slightly better than what you measured.
Have you thought about trying to optimize the hash function for your data? You should be able to find a set of random numbers that give many fewer collisions if you try a few billion.
Well, if you want to go down that route, you can use what's known as perfect hashing. But those functions are typically somewhat more expensive to evaluate, so just iterating down a few buckets is probably worth it.
If you try modifying the existing hash values, you mess with a lot more than just the tablebases. That may or may not be harmless.
syzygy wrote: ↑Mon Jun 04, 2018 1:10 am
According to this page, the average number of probes for successful find is estimated to be
For alpha = 3002/4096, this gives 2.372. So what you measured is better than expected.
For alpha = 3002/8192, we get 1.289, which is slightly better than what you measured.
Have you thought about trying to optimize the hash function for your data? You should be able to find a set of random numbers that give many fewer collisions if you try a few billion.
The current hash function basically comes for free (it is based on the material signature key).
Sesse wrote: ↑Sun Jun 10, 2018 9:01 am
Generation passed 5 TB; I guess that's somewhat of a milestone. I assume we're getting more precise estimates of the end size now, too?
Maybe compare 5 TB to remaning sets to be generated.