flok wrote: ↑Wed May 08, 2019 2:01 pm
Hi,
Thank you for your reply.
Am I right that UCTS is only a matter of selecting which node to explore?
So I apply
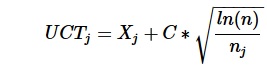
to each root-node and that's it?
Like:
- for each root-move, calculate a score (UCTj)
- find move with highest score and then do a play-out on it
If so: should I then first do a few try-playouts for each root-move to have initial values for that formula?
I am not sure what the scientific correct term is for doing monte carlo playouts at root node versus storing the expanded search tree with the according values.
If you want to guide the search via UCT or another method, you will have to store the expanded search tree in memory, not only the root moves. You will need to add an expansion phase to your algorithm, that adds the expanded node to the stored search tree.
I am more into Best First search, but iirc, you can set a parameter in UCT that defines how many playouts have to be played before you expand and add the children of a node to the search tree in memory. For example,
1) select a node (via UCB1 formula ) from search tree in memory until unexpanded node reached
3) if root or playouts > n then expand (add children to tree), goto 1
3) perform a playout, update counters and values of node
4) propagate the results back through the tree in memory
5) goto 1
--
Srdja