Code: Select all
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%)
1 master : 0.0 ---- 55594.5 106111 52 100
2 SV : -10.0 1.9 20633.5 42472 49 99
3 run79/run2/scale361 : -14.5 3.2 7668.5 16000 48 100
1. A ton of experimentation on the best data to use. Current best data uses generated games with a fair bit of randomness, then rescored using a d9 pass after the fact.
2. Switching to using the ranger optimizer: https://github.com/lessw2020/Ranger-Dee ... -Optimizer
3. Visualizing the activations of the net, discovering that the pytorch trained nets had numerous dead neurons. That led to further tuning of the optimizer parameters (in particular, the ADAM eps value had a large effect on the dead neurons - suspicion is this comes from the very low loss values that we typically see during training). See https://github.com/glinscott/nnue-pytorch/issues/17 and https://github.com/official-stockfish/S ... ssues/3274 for background.
Eg. compare master net:
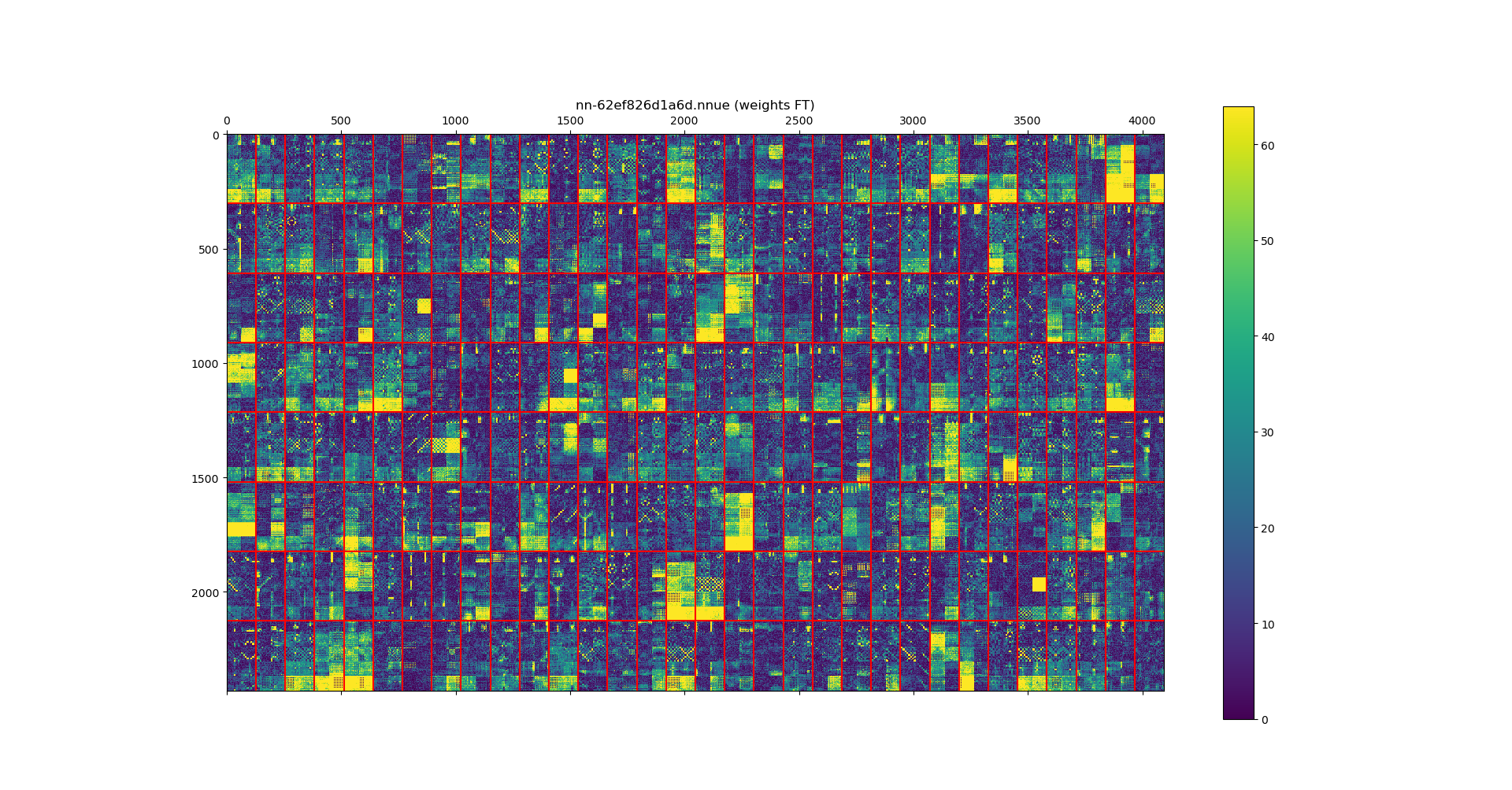
vs old pytorch net:

4. Switching scaling of the evaluations to 361 from 600 (I had mentioned this earlier, but it did end up being beneficial).
5. Introducing learning rate drops by 0.3x every 75 epochs.
6. Shuffling the input data. We do multiple passes through the data, so shuffling helped a lot.
7. Only using every N positions in the data (eg. 7). This helps so that each batch gets to see more variety of games, as opposed to a bunch of positions from one game. We end up seeing all the data in multiple passes through, so it doesn't reduce the effective data size.
8. Reducing batch size from 16384 to 8192.