Adam Hair wrote:My thought was to use the average or median from all of the games instead of plotting each game.
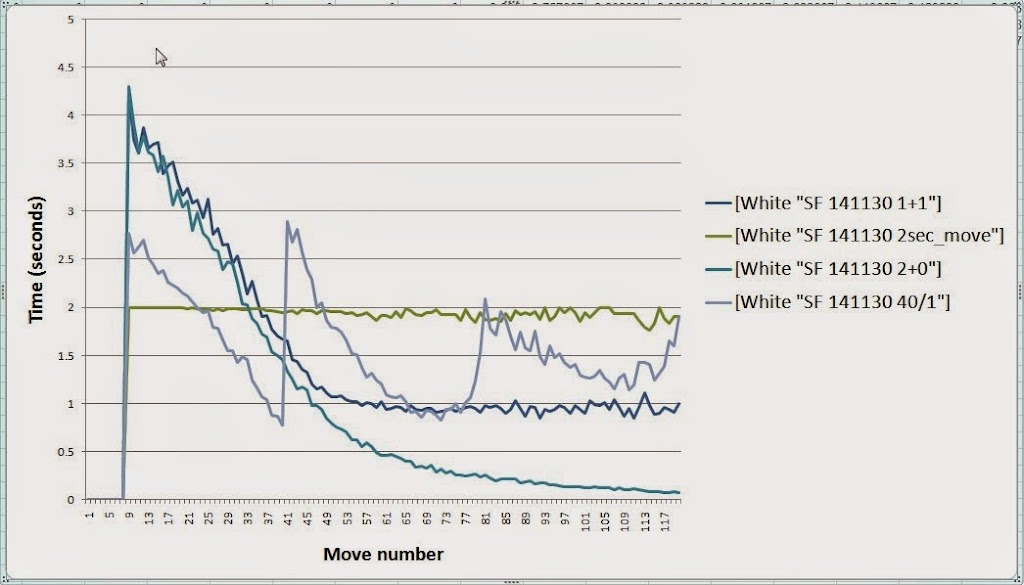
Here is the average time in seconds for 300 games per engine. I have records for each color and only showing the white side. Moves selected is only up to 120 moves.
Moves before 40 really matters, The 1+1 still has the stamina to continue beyond that move.
Adam Hair wrote:Thanks! The graph really explains the results.
Explanation is a bit harder. 1+1 and 2+0 are in competition for all three top engines for testing framework as strength versus time used goes. One of two:
1/ Time management of 2+0 can be improved.
2/ Use more games allowed by 2+0 compared to 1+1 for same time used, with no much strength loss.
Another thing to mention is that adjudication rules play a role here. I don't know which you used, but I think the average game without adjudication would be 5-10 moves longer. If time management knew what are the rules, I think 1+1 and 2+0 would be even closer matched in strength, with some time saving for 2+0.
Self play is not measuring strength. Self play measures differences,
But more differences is not more strength. So it can happen that if you have a version that wins against all other versions of the same chess engine, this winner is not really stronger against other chess programs. It's unimportant if your game base is 500 or 5000000 games, the problem is the same.
The engine that is the winner is not the stronger engine.
Therefore self play is wasting time.
What seems like a fairy tale today may be reality tomorrow.
Here we have a fairy tale of the day after tomorrow....
mclane wrote:Self play is not measuring strength. Self play measures differences,
But more differences is not more strength. So it can happen that if you have a version that wins against all other versions of the same chess engine, this winner is not really stronger against other chess programs. It's unimportant if your game base is 500 or 5000000 games, the problem is the same.
The engine that is the winner is not the stronger engine.
Therefore self play is wasting time.
If self play was a waste of time, then most of the top active engines would not be making any progress.
Besides, this is not a comparison of various engines at various time controls. We do not know if SF would score better than Houdini at 1'+1" than at 40/1'. But we can see that SF plays at a higher level at 1'+1" than at 40/1'.
Laskos wrote:Another thing to mention is that adjudication rules play a role here. I don't know which you used, but I think the average game without adjudication would be 5-10 moves longer. If time management knew what are the rules, I think 1+1 and 2+0 would be even closer matched in strength, with some time saving for 2+0.
Hopefully it only plays a small role in this case. The resign threshold was 300cp for 3 moves, and the games were adjudicated as draws if 250 moves were played and the eval was less than +/- 50cp. There should have been no resign threshold. I copied and pasted the cutechess script from another test I was doing and forgot to remove the resign switch.
Given that these are UCI engines, I do not think they are sent the adjudication rules nor would they know what to do with the information.
Adam Hair wrote:Thanks! The graph really explains the results.
Explanation is a bit harder. 1+1 and 2+0 are in competition for all three top engines for testing framework as strength versus time used goes. One of two:
1/ Time management of 2+0 can be improved.
2/ Use more games allowed by 2+0 compared to 1+1 for same time used, with no much strength loss.
The difference between 1+1 and 2+0 is muted somewhat by the high draw rate (71.5%). However, I think you are correct that 2'+0" is a better choice than 1'+1" for testing. And perhaps even better would be 2' plus some small increment (perhaps 50 millisec increment like the Stockfish framework uses).