
Well, I was talking from past experience, and testing it was not trivial as I had no easy way to create an UTF-8 file in the first place. It appears you are right as far as NotePad is concerned. But with WordPad. Which is what I normally have to use on files imported from Linux, as NotePad would forge everything into a single line there.Fulvio wrote: ↑Sun Nov 14, 2021 5:21 pm This shows that you do not know the subject at all and explains all the nonsense statements.
Create a UTF-8 text file (without BOM which is used to identify endianess and is not needed and is not recommended for UTF-8) and then open it with Windows Notepad and you will see that it displays correctly.
Generally speaking, when you are convinced that you are the only one who is right, and the rest of the world is wrong, it is worth taking some time to think about it better.
When I copy-paste some text with non-ascii symbols (I used "het Kröller-Müller Museum") into NotePad, and save, it creates this file:
Code: Select all
0000000 150 145 164 040 113 162 366 154 154 145 162 055 115 374 154 154
0000020 145 162 040 115 165 163 145 165 155 015 012
0000033
When I upload this file to my website, access it with FireFox from Linux, it also displays correctly. When I copy-paste it from FireFox into gedit, it still displays correctly. When I save it from gedit, though, I get
Code: Select all
0000000 150 145 164 040 113 162 303 266 154 154 145 162 055 115 303 274
0000020 154 154 145 162 040 115 165 163 145 165 155 012 012
0000035
Now I open this UTF-8 file with WordPad, and get to see this:
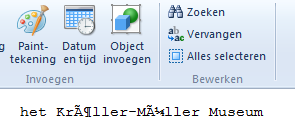
This doesn't look so good anymore... It shows exactly the effect I described: the UTF-8 bytes are interpreted as if they were Latin-1 characters.
Now the amazing thing is that when I save this file from WordPad, and load it into NotePad, I do get the ö and ü back. Which of course should count as an error: it was not what WordPad diaplayed, and NotePad could not possibly know I did not actually mean to write what WordPad displayed: "het Kröller-Müller Museum". Which is what I get on TalkChess when I copy-paste it from the WordPad display. Saving it and reading it Back into NotePad should have given me the same thing.
So it seems these newer versions of NotePad are cheating to make it appear they do something that is logically impossible: judge if a file should be interpreted as UTF-8 or Latin-1. I have no idea what algorithm it uses for that. Perhaps when all non-ascii sequences are valid UTF-8 it guesses that the file is UTF-8 encoded. This can be a wrong guess, especially when there are very few non-ascii characters in the file.