The problem with this kind of stuff is that it is so much dependent on the internal board and move representation of the GUI.Don wrote:Why not add move generation and move validation? Obviously you do this in a modular way to support chess variants, the idea being that each variant has a separate "plug-in" with the same interface. I call it a plug-in but it could part of the library.
Feedback request: libchessinterface
Moderator: Ras
-
hgm

- Posts: 28481
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Feedback request: libchessinterface
-
Don

- Posts: 5106
- Joined: Tue Apr 29, 2008 4:27 pm
Re: Feedback request: libchessinterface
For the GUI designer there is no way around the fact that there is no automated way to instantly play any game without special considerations that would go beyond the protocol. If someone created some strange new game that you wanted to support, you would have to do additional work. I don't know what "zillioins of games" does for things like this and I understand it's a complex problem.hgm wrote:The problem with this kind of stuff is that it is so much dependent on the internal board and move representation of the GUI.Don wrote:Why not add move generation and move validation? Obviously you do this in a modular way to support chess variants, the idea being that each variant has a separate "plug-in" with the same interface. I call it a plug-in but it could part of the library.
But one issue with any GUI is that it should not depend on the engine (which might be buggy) to determine whether a move is legal or not, so a proper implementation of the Xboard or UCI protocol needs a move validator. Did the engine make a legal move? Is the game over? One such issue is the important and export format of moves. In chess UCI and Winboard use long algebraic but a quality GUI displays SAN notation. For any game there should be methods to present a convent representation (long algebraic in chess) and the "official" representation that is most natural for the players (SAN in chess.) In some games the may be the same but they should still be there.
That won't solve every problem for the GUI author, but I cannot believe it wouldn't help. Also, a UCI or Xboard protocol library cannot be complete or correct without this.
I would imagine that with some effort and imagination the "plugin" could go a long way towards making it easier for the GUI designer. Imagine building a chess interface but not knowing anything about the rules. This special library could tell you when there was a draw by repetition, insufficent material, stalemate and so on and so forth. Some abstract protocol for representing how the board changes would be very convenient. One could identify many of the common cases for these variants, such as promotions and drops and such so that the GUI would have a consistent way to present them to the user and would be handled by the library.
So I think you could build a GUI that handled any chess-like game that was not too weird if you restrict it to games with drops, promotions, and perhaps one or two other common cases seen in these variants where the GUI designer only needs a plugin and piece graphics for all the various piece types. The plugin is written only once for any game and abstracts away the complexities.
But I defer to you on this because you have a lot more experience with variants. My experience is that what seems simple ends up being no so simple once you get into it.
Capital punishment would be more effective as a preventive measure if it were administered prior to the crime.
-
hgm
- Posts: 28481
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Feedback request: libchessinterface
I have thought about replacing the XBoard move generator by a table-driven one, using the same move-description system as Fairy-Max. But Fairy-Max is by no means completely general, even for Chess variants. I think in Zillions the game-description files basically are programs in their own right, defining each piece with a Lisp-like routine. That way you can do everything. Fairy-Max already cannot handle pieces whose moves differ depending on their location on the board (and thus cannot handle pieces restricted to a part of the board, like in Xiangqi).
We have a different (rather opposite) philosophy on GUI development. In my view the task of a GUI is to handle display and mouse input, and I would like it to do that in a way that is as independent as possible from the game rules. Because that would put the least restrictions on its possible applications. If rule knowledge is required (e.g. for highlighting possible destination squares of a 'lifted' piece, or for converting a coordinate move to SAN) it should best be delegated to a separate 'plugin' module. Which could be a separate process communicating with it through pipes, purely text based, not unlike an engine.
In fact what such a 'referee module' would have to do is so close to what a regular WB engine does, that it doesn't really help to make a distinction between the two. A referee module is simply a non-buggy engine that fully implements the protocol. Availability of a referee engine would allow the author of a new engine to create a stripped-down version, only partially supporting the protocol (e.g. skip legality-checking on the input move). And if you are writing the first and only engine for a new variant, the engine can simply be its own referee, when the referee protocol is a not-too-large and straightforward extension of the engine protocol.
The extensions to WB protocol Daniel and I developed for the WinBoard Alien Edition go in that direction. Basically the only additions that were needed to get full GUI functionality for Chess variants with rules completely unknown to the GUI was to inform the referee of individual mouse clicks (so it can already react on selection of a from square, e.g. to implement one-click moving), and a way to indicate highlighting of board squares (e.g. to indicate allowed to-squares). For more complex, non-Chess-like games (like Ultima or Atomic Chess) it was necessary to allow the engine to send a complete board update (as FEN) to the GUI. But that is pretty much all.
The main problem that is bugging me is how to let a user enter a multi-step move. E.g. a Lion in Chu Shogi can move two times per turn, as an orthodox King, but it is not obligatory to make the second step. So if the user enters Le4xf5, how is the GUI to know whether he is now done, or whether he intends to make a second step Lf5-g5? It would be nice if there was a general (rule-free) entry method for such moves, through kludges not unlike the KxR method for entering Chess960 castling. (E.g. first drag the victim of the first Lion step onto the Lion (f5xe4), and then move the Lion to its destination (e4-g5). This could also be used to enter non-standard e.p. captures: drag the enemy Pawn onto your own, and then play the Pawn move. More difficult is to handle multi-piece moves like non-standard castlings that need the user to indicate both King and Rook destination. Perhaps this can be done by first 'stacking' all pieces you want to move on one square (e.g. play Ra1xKe1 to stack the Rook under the King on e1), and then start 'unstacking' from that square to the final destinations (i.e. play Ke1-b1 to uncover the Rook, and then Re1-d1 to place the Rook)).
We have a different (rather opposite) philosophy on GUI development. In my view the task of a GUI is to handle display and mouse input, and I would like it to do that in a way that is as independent as possible from the game rules. Because that would put the least restrictions on its possible applications. If rule knowledge is required (e.g. for highlighting possible destination squares of a 'lifted' piece, or for converting a coordinate move to SAN) it should best be delegated to a separate 'plugin' module. Which could be a separate process communicating with it through pipes, purely text based, not unlike an engine.
In fact what such a 'referee module' would have to do is so close to what a regular WB engine does, that it doesn't really help to make a distinction between the two. A referee module is simply a non-buggy engine that fully implements the protocol. Availability of a referee engine would allow the author of a new engine to create a stripped-down version, only partially supporting the protocol (e.g. skip legality-checking on the input move). And if you are writing the first and only engine for a new variant, the engine can simply be its own referee, when the referee protocol is a not-too-large and straightforward extension of the engine protocol.
The extensions to WB protocol Daniel and I developed for the WinBoard Alien Edition go in that direction. Basically the only additions that were needed to get full GUI functionality for Chess variants with rules completely unknown to the GUI was to inform the referee of individual mouse clicks (so it can already react on selection of a from square, e.g. to implement one-click moving), and a way to indicate highlighting of board squares (e.g. to indicate allowed to-squares). For more complex, non-Chess-like games (like Ultima or Atomic Chess) it was necessary to allow the engine to send a complete board update (as FEN) to the GUI. But that is pretty much all.
The main problem that is bugging me is how to let a user enter a multi-step move. E.g. a Lion in Chu Shogi can move two times per turn, as an orthodox King, but it is not obligatory to make the second step. So if the user enters Le4xf5, how is the GUI to know whether he is now done, or whether he intends to make a second step Lf5-g5? It would be nice if there was a general (rule-free) entry method for such moves, through kludges not unlike the KxR method for entering Chess960 castling. (E.g. first drag the victim of the first Lion step onto the Lion (f5xe4), and then move the Lion to its destination (e4-g5). This could also be used to enter non-standard e.p. captures: drag the enemy Pawn onto your own, and then play the Pawn move. More difficult is to handle multi-piece moves like non-standard castlings that need the user to indicate both King and Rook destination. Perhaps this can be done by first 'stacking' all pieces you want to move on one square (e.g. play Ra1xKe1 to stack the Rook under the King on e1), and then start 'unstacking' from that square to the final destinations (i.e. play Ke1-b1 to uncover the Rook, and then Re1-d1 to place the Rook)).
-
Don
- Posts: 5106
- Joined: Tue Apr 29, 2008 4:27 pm
Re: Feedback request: libchessinterface
I don't think I have a well formed philosophy concerning that - more than one road leads to Rome as they say. One is not necessary more valid than the other.hgm wrote:I have thought about replacing the XBoard move generator by a table-driven one, using the same move-description system as Fairy-Max. But Fairy-Max is by no means completely general, even for Chess variants. I think in Zillions the game-description files basically are programs in their own right, defining each piece with a Lisp-like routine. That way you can do everything. Fairy-Max already cannot handle pieces whose moves differ depending on their location on the board (and thus cannot handle pieces restricted to a part of the board, like in Xiangqi).
We have a different (rather opposite) philosophy on GUI development.
But I do take the point of view that as an engine developer I don't want to deal with GUI any more than I have to. I'm not saying that is "right" way, it's just my preference. I guess I prefer the Unix way of doing things which is summed up as doing only one thing but doing it well. If I could I would separate the evaluation function in Komodo as a separate program that only evaluates - only problem is that the search and evaluation are way too tightly coupled to make that practical but that is really the more "correct" way, at least in an idealistic sense.
If you take the point of view that the GUI is just a library for the engine developer to use as a "canvas" to take care of the graphic and mouse, then you have a very different thing - you are just one hop skip and jump away from making it a library that you link in to your program. I agree that it gives the engine more say about low level details but that is not what I need. If it affected the strength of the program in any noticeable way I would change over to it.
I see the choice of protocol as something more abstract that just running a GUI for a chess program. It can be used to build tools that don't play chess for example but still communicate with an engine, perhaps to rank moves or some other function.
As it turns out I don't think it matters much because both protocols are plenty good to build pretty much any tool that needs to communicate with a chess program to do just about any thing. I could make up 20 different tools and we would both probably say, "Oh that is easy, you just do this ...." and it would work.
I'll be completely honest with you on this. I hate both protocols and think they both suck and have too many warts. But I appreciate the challenges of trying to improve either one and I know it's far from being an easy task.
The approach I would use if I were building this libchessinterface? I would design a new protocol from scratch, based on peoples "objective" experiences with both protocols, what they like, what they hate, what should be improved, etc .... Then this library would be a bridge between all 3 protocols with the recommendation to use the new protocol in any new chess programs. Unfortunately I know that getting agreement on how a new protocol should look and what should be the design goals would end up being a huge argument because most people do not know how to think objectively about such things - they prefer what they are used to. For example I cannot see you ever being objective about this issue as you are essentially "married" due to your heavy involvement with xboard. By the same token many are "married" to UCI, often because they never tried anything else. Most of the arguments for and against are silly or just nitpicks, they are the equivalent of arguing over program indentation. But some are real issues.
I have several against UCI but near the top of my list is the limitation of data types. Occasionally we are tuning something in Komodo that we express as a floating point value - and we have to express it as an integer. So we might have to call it a percent, or a centi-unit or something to work around this. Nitpicking? Maybe. But more seriously UCI badly needs a data type to express the location of a file. A file path is not a "string", it's something else and a GUI cannot validate one of these if it doesn't know it's supposed to be a file.
I would have a difficult time designing a protocol because I am torn between a couple of issues. One of them that is built in to the UCI and xboard protocol is this assumption that a program follows a very strict pattern of iterative deepening, looking at the moves in strict order at the root and so on. Before you say anything, yes, you can work around these things. But imagine a program that uses a Monte Carlo Tree Search which is a BIG DEAL in Go these days. It would be completely awkward to use a modern Chess GUI for a program designed this way. In fact even MP programs can be designed in a way that does not naturally "fit" into the fixed paradigm of these protocols.
I don't know what to do about this (if I were designing a more flexible protocol) because things get more complicated if you try to provide too much flexibility - this iterative deepening paradigm is precisely the kind of information you WANT to see displayed in modern chess GUI 99% of the time.
In Komodo we almost switched to iterating by 1/2 ply. There were some real advantages, but in the end it did not work for us. But imagine what would have happened if it DID work. It's not clear which hacks we would have to apply to make this not look too confusing to users. Probably doing nothing would work, but how would the user know which half ply you were on if he were not looking carefully? Yes, you could report in half ply, if the program says 11 it really means iteration 5 1/2. We sort of got a belly full of this with Rybka, what it reported was not the intended meaning and people did not like this.
Given that you are going to use the "normal" iterative protocol I would like to know the exact moment an iteration is complete. I don't think that is strictly defined in the UCI protocol. Komodo reports in UCI "info depth 7" by itself which is the precise moment it finishes the 6th iteration and starts the 7th but I don't really know if the 6th was finished if it times out as the 7th won't be started in this case. So all this fuss and I still don't have reporting that is all that great.
I also believe a good protocol should be user extendable. If I wanted to support some interesting feature in a GUI that was not provided for in the protocol, I should be able to add this feature anyway, define the extension in a natural way, and then query the engine to see if it's supported. The GTP for GO allows for these extensions. On initialization a UCI program already advertises it's options, so it could also advertise any extensions that it supports.
As an example extension that would be very useful for analysis, suppose you could pass a "tree" to the search function to cause it to restrict it's search to the moves in the tree (and beyond.) In UCI it might look like the searchmoves command but parenthesis could be placed in the list to define the tree and the user interface could provide functions to manipulate the tree according the users wishes. That's just an example but if a GUI wanted to support that it would only do so if the engine advertised support for that feature.
In my view the task of a GUI is to handle display and mouse input, and I would like it to do that in a way that is as independent as possible from the game rules. Because that would put the least restrictions on its possible applications. If rule knowledge is required (e.g. for highlighting possible destination squares of a 'lifted' piece, or for converting a coordinate move to SAN) it should best be delegated to a separate 'plugin' module. Which could be a separate process communicating with it through pipes, purely text based, not unlike an engine.
In fact what such a 'referee module' would have to do is so close to what a regular WB engine does, that it doesn't really help to make a distinction between the two. A referee module is simply a non-buggy engine that fully implements the protocol. Availability of a referee engine would allow the author of a new engine to create a stripped-down version, only partially supporting the protocol (e.g. skip legality-checking on the input move). And if you are writing the first and only engine for a new variant, the engine can simply be its own referee, when the referee protocol is a not-too-large and straightforward extension of the engine protocol.
The extensions to WB protocol Daniel and I developed for the WinBoard Alien Edition go in that direction. Basically the only additions that were needed to get full GUI functionality for Chess variants with rules completely unknown to the GUI was to inform the referee of individual mouse clicks (so it can already react on selection of a from square, e.g. to implement one-click moving), and a way to indicate highlighting of board squares (e.g. to indicate allowed to-squares). For more complex, non-Chess-like games (like Ultima or Atomic Chess) it was necessary to allow the engine to send a complete board update (as FEN) to the GUI. But that is pretty much all.
The main problem that is bugging me is how to let a user enter a multi-step move. E.g. a Lion in Chu Shogi can move two times per turn, as an orthodox King, but it is not obligatory to make the second step. So if the user enters Le4xf5, how is the GUI to know whether he is now done, or whether he intends to make a second step Lf5-g5? It would be nice if there was a general (rule-free) entry method for such moves, through kludges not unlike the KxR method for entering Chess960 castling. (E.g. first drag the victim of the first Lion step onto the Lion (f5xe4), and then move the Lion to its destination (e4-g5). This could also be used to enter non-standard e.p. captures: drag the enemy Pawn onto your own, and then play the Pawn move. More difficult is to handle multi-piece moves like non-standard castlings that need the user to indicate both King and Rook destination. Perhaps this can be done by first 'stacking' all pieces you want to move on one square (e.g. play Ra1xKe1 to stack the Rook under the King on e1), and then start 'unstacking' from that square to the final destinations (i.e. play Ke1-b1 to uncover the Rook, and then Re1-d1 to place the Rook)).
Capital punishment would be more effective as a preventive measure if it were administered prior to the crime.
-
Don
- Posts: 5106
- Joined: Tue Apr 29, 2008 4:27 pm
Re: Feedback request: libchessinterface
Just an addendum to this post and a few more nitpicks:
UCI commands:
go depth 10 ; what if I design a program that has no concept of iteration?
How do I express a list of values, something that would be useful for Larry and I when developing? If we have to do such a thing I will generally build it into a string and I have routines to parse these values but in a GUI should I want to do that it will be a hack.
What if want to express scores in millipawns instead of centipawns? In my opinion output for most things (where it makes sense) should be expressed as floating point values, nothing else makes sense. In UCI time is in milliseconds. The move times for low depth search come out as ZERO.
Don
UCI commands:
go depth 10 ; what if I design a program that has no concept of iteration?
How do I express a list of values, something that would be useful for Larry and I when developing? If we have to do such a thing I will generally build it into a string and I have routines to parse these values but in a GUI should I want to do that it will be a hack.
What if want to express scores in millipawns instead of centipawns? In my opinion output for most things (where it makes sense) should be expressed as floating point values, nothing else makes sense. In UCI time is in milliseconds. The move times for low depth search come out as ZERO.
Don
Don wrote:I don't think I have a well formed philosophy concerning that - more than one road leads to Rome as they say. One is not necessary more valid than the other.hgm wrote:I have thought about replacing the XBoard move generator by a table-driven one, using the same move-description system as Fairy-Max. But Fairy-Max is by no means completely general, even for Chess variants. I think in Zillions the game-description files basically are programs in their own right, defining each piece with a Lisp-like routine. That way you can do everything. Fairy-Max already cannot handle pieces whose moves differ depending on their location on the board (and thus cannot handle pieces restricted to a part of the board, like in Xiangqi).
We have a different (rather opposite) philosophy on GUI development.
But I do take the point of view that as an engine developer I don't want to deal with GUI any more than I have to. I'm not saying that is "right" way, it's just my preference. I guess I prefer the Unix way of doing things which is summed up as doing only one thing but doing it well. If I could I would separate the evaluation function in Komodo as a separate program that only evaluates - only problem is that the search and evaluation are way too tightly coupled to make that practical but that is really the more "correct" way, at least in an idealistic sense.
If you take the point of view that the GUI is just a library for the engine developer to use as a "canvas" to take care of the graphic and mouse, then you have a very different thing - you are just one hop skip and jump away from making it a library that you link in to your program. I agree that it gives the engine more say about low level details but that is not what I need. If it affected the strength of the program in any noticeable way I would change over to it.
I see the choice of protocol as something more abstract that just running a GUI for a chess program. It can be used to build tools that don't play chess for example but still communicate with an engine, perhaps to rank moves or some other function.
As it turns out I don't think it matters much because both protocols are plenty good to build pretty much any tool that needs to communicate with a chess program to do just about any thing. I could make up 20 different tools and we would both probably say, "Oh that is easy, you just do this ...." and it would work.
I'll be completely honest with you on this. I hate both protocols and think they both suck and have too many warts. But I appreciate the challenges of trying to improve either one and I know it's far from being an easy task.
The approach I would use if I were building this libchessinterface? I would design a new protocol from scratch, based on peoples "objective" experiences with both protocols, what they like, what they hate, what should be improved, etc .... Then this library would be a bridge between all 3 protocols with the recommendation to use the new protocol in any new chess programs. Unfortunately I know that getting agreement on how a new protocol should look and what should be the design goals would end up being a huge argument because most people do not know how to think objectively about such things - they prefer what they are used to. For example I cannot see you ever being objective about this issue as you are essentially "married" due to your heavy involvement with xboard. By the same token many are "married" to UCI, often because they never tried anything else. Most of the arguments for and against are silly or just nitpicks, they are the equivalent of arguing over program indentation. But some are real issues.
I have several against UCI but near the top of my list is the limitation of data types. Occasionally we are tuning something in Komodo that we express as a floating point value - and we have to express it as an integer. So we might have to call it a percent, or a centi-unit or something to work around this. Nitpicking? Maybe. But more seriously UCI badly needs a data type to express the location of a file. A file path is not a "string", it's something else and a GUI cannot validate one of these if it doesn't know it's supposed to be a file.
I would have a difficult time designing a protocol because I am torn between a couple of issues. One of them that is built in to the UCI and xboard protocol is this assumption that a program follows a very strict pattern of iterative deepening, looking at the moves in strict order at the root and so on. Before you say anything, yes, you can work around these things. But imagine a program that uses a Monte Carlo Tree Search which is a BIG DEAL in Go these days. It would be completely awkward to use a modern Chess GUI for a program designed this way. In fact even MP programs can be designed in a way that does not naturally "fit" into the fixed paradigm of these protocols.
I don't know what to do about this (if I were designing a more flexible protocol) because things get more complicated if you try to provide too much flexibility - this iterative deepening paradigm is precisely the kind of information you WANT to see displayed in modern chess GUI 99% of the time.
In Komodo we almost switched to iterating by 1/2 ply. There were some real advantages, but in the end it did not work for us. But imagine what would have happened if it DID work. It's not clear which hacks we would have to apply to make this not look too confusing to users. Probably doing nothing would work, but how would the user know which half ply you were on if he were not looking carefully? Yes, you could report in half ply, if the program says 11 it really means iteration 5 1/2. We sort of got a belly full of this with Rybka, what it reported was not the intended meaning and people did not like this.
Given that you are going to use the "normal" iterative protocol I would like to know the exact moment an iteration is complete. I don't think that is strictly defined in the UCI protocol. Komodo reports in UCI "info depth 7" by itself which is the precise moment it finishes the 6th iteration and starts the 7th but I don't really know if the 6th was finished if it times out as the 7th won't be started in this case. So all this fuss and I still don't have reporting that is all that great.
I also believe a good protocol should be user extendable. If I wanted to support some interesting feature in a GUI that was not provided for in the protocol, I should be able to add this feature anyway, define the extension in a natural way, and then query the engine to see if it's supported. The GTP for GO allows for these extensions. On initialization a UCI program already advertises it's options, so it could also advertise any extensions that it supports.
As an example extension that would be very useful for analysis, suppose you could pass a "tree" to the search function to cause it to restrict it's search to the moves in the tree (and beyond.) In UCI it might look like the searchmoves command but parenthesis could be placed in the list to define the tree and the user interface could provide functions to manipulate the tree according the users wishes. That's just an example but if a GUI wanted to support that it would only do so if the engine advertised support for that feature.
In my view the task of a GUI is to handle display and mouse input, and I would like it to do that in a way that is as independent as possible from the game rules. Because that would put the least restrictions on its possible applications. If rule knowledge is required (e.g. for highlighting possible destination squares of a 'lifted' piece, or for converting a coordinate move to SAN) it should best be delegated to a separate 'plugin' module. Which could be a separate process communicating with it through pipes, purely text based, not unlike an engine.
In fact what such a 'referee module' would have to do is so close to what a regular WB engine does, that it doesn't really help to make a distinction between the two. A referee module is simply a non-buggy engine that fully implements the protocol. Availability of a referee engine would allow the author of a new engine to create a stripped-down version, only partially supporting the protocol (e.g. skip legality-checking on the input move). And if you are writing the first and only engine for a new variant, the engine can simply be its own referee, when the referee protocol is a not-too-large and straightforward extension of the engine protocol.
The extensions to WB protocol Daniel and I developed for the WinBoard Alien Edition go in that direction. Basically the only additions that were needed to get full GUI functionality for Chess variants with rules completely unknown to the GUI was to inform the referee of individual mouse clicks (so it can already react on selection of a from square, e.g. to implement one-click moving), and a way to indicate highlighting of board squares (e.g. to indicate allowed to-squares). For more complex, non-Chess-like games (like Ultima or Atomic Chess) it was necessary to allow the engine to send a complete board update (as FEN) to the GUI. But that is pretty much all.
The main problem that is bugging me is how to let a user enter a multi-step move. E.g. a Lion in Chu Shogi can move two times per turn, as an orthodox King, but it is not obligatory to make the second step. So if the user enters Le4xf5, how is the GUI to know whether he is now done, or whether he intends to make a second step Lf5-g5? It would be nice if there was a general (rule-free) entry method for such moves, through kludges not unlike the KxR method for entering Chess960 castling. (E.g. first drag the victim of the first Lion step onto the Lion (f5xe4), and then move the Lion to its destination (e4-g5). This could also be used to enter non-standard e.p. captures: drag the enemy Pawn onto your own, and then play the Pawn move. More difficult is to handle multi-piece moves like non-standard castlings that need the user to indicate both King and Rook destination. Perhaps this can be done by first 'stacking' all pieces you want to move on one square (e.g. play Ra1xKe1 to stack the Rook under the King on e1), and then start 'unstacking' from that square to the final destinations (i.e. play Ke1-b1 to uncover the Rook, and then Re1-d1 to place the Rook)).
Capital punishment would be more effective as a preventive measure if it were administered prior to the crime.
-
hgm
- Posts: 28481
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Feedback request: libchessinterface
Well, I don't really consider myself married to the XBoard protocol. I alter it all the time. It is more that I am of the opinion that creating new protocols to do things that old protocols are already doing hardly ever makes the world a better place. It usually just adds to the Babylonic confusion.Don wrote:For example I cannot see you ever being objective about this issue as you are essentially "married" due to your heavy involvement with xboard.
Indeed, we did recognize that important difference between filename, pathname and arbitrary text when defining XBoard protocol. In UCI it is of course also easily repaired, and UCI3 seems to do exactly that. But unfortunately UCI is pretty much a 'dead' protocol, carved into stone in all its imperfections. So such improvements do not find general acceptance.I have several against UCI but near the top of my list is the limitation of data types. Occasionally we are tuning something in Komodo that we express as a floating point value - and we have to express it as an integer. So we might have to call it a percent, or a centi-unit or something to work around this. Nitpicking? Maybe. But more seriously UCI badly needs a data type to express the location of a file. A file path is not a "string", it's something else and a GUI cannot validate one of these if it doesn't know it's supposed to be a file.
I think one simply should not be too strict on this. The protocol allows you to report several different numbers, as well as free-format strings. You can use those to report that info which seems relevant for your engine. For instance, I equiped my 'fairygen' tablebase generator with a WB interface, so you can run it as an engine, and play against the tablebase it generates. Obviously the inner workings of it are completely different from those of a conventional engine. But it was perfectly possible to let it produce 'thinking output' that would display a nice table of the number of positions for each DTM in the Engine Output window during building. And then a table of moves with the resulting DTM when it plays:One of them that is built in to the UCI and xboard protocol is this assumption that a program follows a very strict pattern of iterative deepening, looking at the moves in strict order at the root and so on. ...
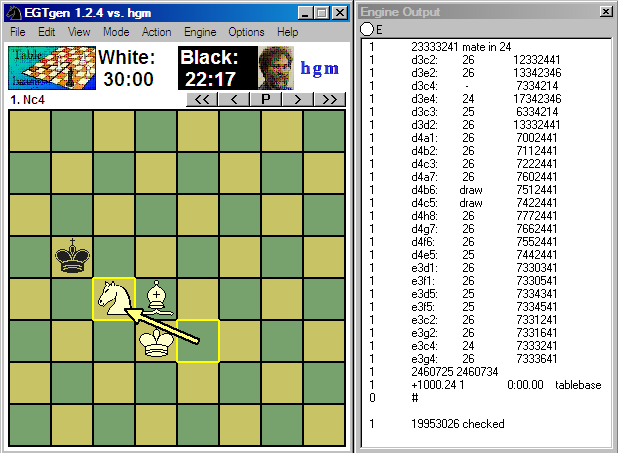
Indeed, this also annoyed me in Fairy-Max. Initially I had it print only one PV, at the end of the iteration, and then you would know exactly. But when I changed it to multi-PV I had to print a PV whenever the old one was overturned, so I moved the printing code to there. That leads to printing of a new PV already after search of the first move completes. But often it then stays at that, so you have no idea when a new iteration starts. Spartacus repeats the best PV at the end of the iteration (with different nodes and time info), but this also looks pretty ugly. I don't know what is a good solution. But I am not sure the protocol is to blame for it. It just requires smarter handling in the GUI (like removing the duplicat).Given that you are going to use the "normal" iterative protocol I would like to know the exact moment an iteration is complete. I don't think that is strictly defined in the UCI protocol....
Well, in XBoard protocol this is implemented in the reverse way, the engine that supports an extension queries the GUI to see if it is supported. I don't think it matters much if you do it one way or the other. The extension can only work if both GUI and engine know about it anyway.I also believe a good protocol should be user extendable. If I wanted to support some interesting feature in a GUI that was not provided for in the protocol, I should be able to add this feature anyway, define the extension in a natural way, and then query the engine to see if it's supported. The GTP for GO allows for these extensions. On initialization a UCI program already advertises it's options, so it could also advertise any extensions that it supports.
In UCI there is no real distinction between engine-defined options and enabling GUI features. But of course you could use dummy options for that purpose (e.g. button options). The only side effect would be that the buttons appear in the Engine Settings dialog on GUIs that do not support the extension, but as pressing them would only lead to a setoption command going to the engine and being ignored by it, that is survivable. The convention that options with names that start with UCI_ are for the GUI and should never be displayed in the Engine Settings dialog, not even by GUIs that do not recognize them as a valid option, would really be helpful here. One of the very annoying things of UCI is that the GUI cannot know if the engine supports searchmoves. Sending "option name UCI_searchmoves type button" with the options as a method to cure this would be really helpful.
Well, "option name UCI_searchtree type button" would be the recommended kludge to do it. But you hit upon what I consider the biggest problem with UCI: that it is not alive, and not amenable to change. If people want to add features to XBoard protocol, the just come here or on WB forum, present their ideas, and if they seem to be harmless, they will be added. (In fact Jonas did so this morning, on WB forum!) It is a living protocol.As an example extension that would be very useful for analysis, suppose you could pass a "tree" to the search function to cause it to restrict it's search to the moves in the tree (and beyond.) In UCI it might look like the searchmoves command but parenthesis could be placed in the list to define the tree and the user interface could provide functions to manipulate the tree according the users wishes. That's just an example but if a GUI wanted to support that it would only do so if the engine advertised support for that feature.
UCI would not be nearly so bad as it is if I were in control of it!
-
JonasThiem
- Posts: 36
- Joined: Sun Sep 02, 2012 5:23 pm
Re: Feedback request: libchessinterface
They probably aren't, but the problem is there in my opinion: incomplete or buggy protocol implementations. It might just be that writing a library might not fix it since everyone continues to use their own incomplete or buggy codemcostalba wrote: IMHO also GUI authors are _not_ waiting for your library: you have a solution looking for a problem..
I'm interested in implementing the protocol layer. I'm not interested in doing a generic movegen with clean code that supports all the countless chess variants (and I would consider a specific one to be not very useful). While the latter would be useful too, I believe the former isn't automatically useless if not bundled with a movegen.mcostalba wrote: You won't go far IMHO. The only motivation you should rely on is to have fun writing your stuff. If this motivation is not enough for you better even don't start.
(Also I don't suggest GUIs rely on engines for move validation, rather that they continue to use their own movegen code up to the day someone comes up with a library that does that too in a satisfying way)
-
Don
- Posts: 5106
- Joined: Tue Apr 29, 2008 4:27 pm
Re: Feedback request: libchessinterface
I encourage you to continue. If it is easy to integrate into my code I'll use it in Komodo if the licensing works for me.JonasThiem wrote:They probably aren't, but the problem is there in my opinion: incomplete or buggy protocol implementations. It might just be that writing a library might not fix it since everyone continues to use their own incomplete or buggy codemcostalba wrote: IMHO also GUI authors are _not_ waiting for your library: you have a solution looking for a problem..so in that regard it's a bit of a gamble and maybe a wasted effort, but as you pointed out I'm doing it for the fun aswell.
I'm interested in implementing the protocol layer. I'm not interested in doing a generic movegen with clean code that supports all the countless chess variants (and I would consider a specific one to be not very useful). While the latter would be useful too, I believe the former isn't automatically useless if not bundled with a movegen.mcostalba wrote: You won't go far IMHO. The only motivation you should rely on is to have fun writing your stuff. If this motivation is not enough for you better even don't start.
(Also I don't suggest GUIs rely on engines for move validation, rather that they continue to use their own movegen code up to the day someone comes up with a library that does that too in a satisfying way)
Capital punishment would be more effective as a preventive measure if it were administered prior to the crime.
-
JonasThiem
- Posts: 36
- Joined: Sun Sep 02, 2012 5:23 pm
Re: Feedback request: libchessinterface
Does Komodo have a GUI? So far I'm only planning to write something for GUI developers as a help... although now that people keep asking for it, I guess creating a library for the engine side might also be a good idea at some point.
-
Giorgio Medeot
- Posts: 52
- Joined: Fri Jan 29, 2010 2:01 pm
- Location: Ivrea, Italy

Re: HGM question: multiple time controls with level
I think it may be a good idea to incorporate it in the specs, since it is more or less settled down, so that it can be referenced and implemented by engine and GUI authors.hgm wrote:I guess this did not find its way in the official specs yet. Because WB does not implement it yet, I guess I never felt the urgency.
Agreed, it seems nice and natural extension. I like the choice of semicolons, too.hgm wrote:In a discussion here, however, I was convinced that the best way to do it in the protocol would be with multiple triples separated by semi-colons, subject to a feature xlevel=1. Implementations are expected to still send a new level command at the start of each new session with deviating parameters, though, when the user has set such a TC and the engine did not explicitly send xlevel=1.
Well, I don't like this one: while handling the possibility of having a negative value implies more or less the same coding effort than adding a new parameter, it seems a little bit wrong - from a conceptual point of view - to reuse the same parameter to provide two orthogonal informations. I agree it is of little practical importance, as I don't expect any user to be willing to set a time control with a delay and an increment. Still, I'd prefer to have a dedicated parameter and keep the possibility to specify both at the same time.hgm wrote:I furthermore plan to let negative INC parameters indicate the specified time is only a maximum, and that you don't get more time added to your clock than you actually used. (b. So that level 0 0 -10 basically becomes 10 sec/move maximum, like st 10 (but usable in a multi-session context). While level 0 5 -10 would specify a Bronstein TC with 5 min initially, and the first 10 sec thinking on each move not deducted from your clock (because it gets added back afterwards, if you used more than 10 sec, and otherwise it gets added what you actually used).
Cheers,
- Giorgio