Dragon is only 30 Elo behind Stockfish. That is not much.
Depends on how you measure it. 30 elo sounds like not much, but that references balanced positions.
In reality the lead that Stockfish has on the rest of the field is absurd.
Stockfish beat Dragon in the CCC19 Bullet (1+1) Final by 81.8 elo.
Torch beat Dragon in the CCC20 Bullet (1+1) Final by 10.8 elo.
Stockfish is now beating Torch in the CCC20 Bullet (1+1) Final by 100.2 elo.
This suggests that Stockfish was, at that time, 71 elo ahead of today's Torch.
This suggests that the new gap between Stockfish and Dragon is 111 elo.
All those games used 250 threads, and the UHO book from Stefan Pohl.
Still, Bullet is just Bullet and will probably be tested with Ponder OFF as well. The timing of longer games is different from that of Bullet. In my private test, which I did with 10 minutes and Ponder ON, it happened that the engines thought about a move for up to 60s.
I'm not interested in these UHO openings. It is difficult to imagine that such positions come about in practice. If you let engines play without a book, the best engines play the complete opening theory flawlessly. Whether Ruy Lopez or Queen's Gambit, whether Sicilian or French or Caro-Kann: Stockfish plays everything perfectly by itself!! If you want e.g. win on the server, then only special killer variants will help. And if the opponent knows them, then nothing helps. Then everything ends in a draw. Even supercomputers with over 1000 threads can't win against 4 threads. This is fact because I created a book for a player who plays with 1500 threads (he plays with EMAN) and got all the games sent to him. Why do I need another engine like Torch here?
If you play normal and well-known openings and you don't rape the engines with dubious variants, then it can be said that there will be no engine that will defeat Stockfish. You can no longer win against Dragon 3.2 on the server if normal books are used.
Deliberately (!) incorrect variants have to be invented in order to win. Who cares? The chess grandmasters are interested in good analyzes for the proven opening theory. I think that besides Stockfish, Lc0 and Dragon are also very good engines. The creation of a whole new engine is actually completely unnecessary. An evolution of Dragon would be better than the new Torch. And Ethereal and other engines are still there as alternatives.
Nobody can convince me that Torch is the better choice, objectively speaking. Torch is only worthwhile for a few programmers and for Chess.com. But not for the rest of the users. Incidentally, I prefer to analyze offline using my favorite GUI than on some server like chess.com, where I have to load the engine as an analysis module.
Eduard wrote: ↑Wed Jul 19, 2023 10:09 pm
Still, Bullet is just Bullet and will probably be tested with Ponder OFF as well. The timing of longer games is different from that of Bullet. In my private test, which I did with 10 minutes and Ponder ON, it happened that the engines thought about a move for up to 60s.
I'm not interested in these UHO openings. It is difficult to imagine that such positions come about in practice.
" ..So, UHO openings are needed, with at least 100000, better more, different opening-lines. So, I decided to develop such UHO XXL openings. What have I done?
Step 1: Built a database out of all games since 1945 of the Megabase 2022 (around 8 million human games) and 3 million human games (2019-2021) out of the LiChess Elite-Database (filtered all (standard) games from lichess to only keep games by players rated 2400+ against players rated 2200+, excluding bullet games.).". https://www.sp-cc.de/uho_xxl_project.htm
Eduard wrote: ↑Wed Jul 19, 2023 10:09 pm
Still, Bullet is just Bullet and will probably be tested with Ponder OFF as well. The timing of longer games is different from that of Bullet. In my private test, which I did with 10 minutes and Ponder ON, it happened that the engines thought about a move for up to 60s.
I'm not interested in these UHO openings. It is difficult to imagine that such positions come about in practice.
" ..So, UHO openings are needed, with at least 100000, better more, different opening-lines. So, I decided to develop such UHO XXL openings. What have I done?
Step 1: Built a database out of all games since 1945 of the Megabase 2022 (around 8 million human games) and 3 million human games (2019-2021) out of the LiChess Elite-Database (filtered all (standard) games from lichess to only keep games by players rated 2400+ against players rated 2200+, excluding bullet games.).". https://www.sp-cc.de/uho_xxl_project.htm
For once, I agree with Eduard.
I am also interested in proper chess with fairly balanced opening lines, rather than bullet chess or chess with contrived opening lines.
If you don't use unbalanced opening books, it will be all draws I'm afraid. Even TCEC uses unbalanced books (though not to the extent of Stefan Pohl's). If you want to test "purely", FRC is definitely an area but again many of the starting positions aren't as balanced.
nmcrazyim5 wrote: ↑Thu Jul 20, 2023 5:35 am
If you don't use unbalanced opening books, it will be all draws I'm afraid........
With top engines only, more like around 80% draw rate.
For other engines, you obviously get a lower to much lower draw rate.
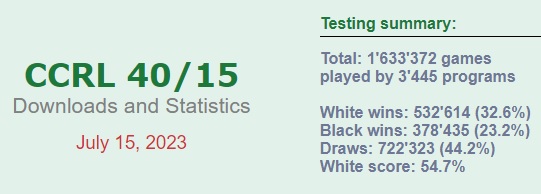
CCRL 40/15 uses fairly balanced books:
For Dragon 3.2 4 cpu on CCRL Rapid I count about 96% draws against the seven opposing engines over 3500 (all SF or SF derivatives of course). Most likely the few decisive games were from openings that would now be considered somewhat dubious, even if they were thought to be reasonably balanced when the books were made. If you use books that never exit with Black more than say 5 centipawns worse than "par" (the initial eval) I think it would be over 99% draws. There are no other valid pairings over 3500 that are not between SF derivates or other Dragon versions.
nmcrazyim5 wrote: ↑Thu Jul 20, 2023 5:35 am
If you don't use unbalanced opening books, it will be all draws I'm afraid........
With top engines only, more like around 80% draw rate.
For other engines, you obviously get a lower to much lower draw rate.
CCRL 40/15 uses fairly balanced books:
For Dragon 3.2 4 cpu on CCRL Rapid I count about 96% draws against the seven opposing engines over 3500 (all SF or SF derivatives of course). Most likely the few decisive games were from openings that would now be considered somewhat dubious, even if they were thought to be reasonably balanced when the books were made. If you use books that never exit with Black more than say 5 centipawns worse than "par" (the initial eval) I think it would be over 99% draws. There are no other valid pairings over 3500 that are not between SF derivates or other Dragon versions.
As long as an evaluation dips below 0.70 for even one move for the first 10 moves out of book, I'm happy.
Eduard wrote: ↑Wed Jul 19, 2023 10:09 pm
I'm not interested in these UHO openings. It is difficult to imagine that such positions come about in practice.
Those positions happen in practice, in HUMAN practice, as the name of the book suggests. The openings don't have random mistakes, they have human mistakes.
Eduard wrote: ↑Wed Jul 19, 2023 10:09 pm
If you let engines play without a book, the best engines play the complete opening theory flawlessly.
Deliberately (!) incorrect variants have to be invented in order to win. Who cares? The chess grandmasters are interested in good analyzes for the proven opening theory.
If top engine X "plays the opening theory flawlessly" but doesn't understand anything the moment it gets out of it, then that engine is worse than engine Y that also plays the opening theory flawlessly but demolishes the competition when its out of "proven opening theory".
Asking the engine to analyze some random position or even play from it both require the engine to understand chess outside of "proven opening theory".
nmcrazyim5 wrote: ↑Thu Jul 20, 2023 5:35 am
If you don't use unbalanced opening books, it will be all draws I'm afraid. Even TCEC uses unbalanced books (though not to the extent of Stefan Pohl's). If you want to test "purely", FRC is definitely an area but again many of the starting positions aren't as balanced.
Graham Banks wrote: ↑Thu Jul 20, 2023 8:34 am
As long as an evaluation dips below 0.70 for even one move for the first 10 moves out of book, I'm happy.
Any good reason for this specific and drawish evaluation?