Can we get some 40x512 nets?
That would also improve our understanding of NN development, NN training, GPU/CPU/NPU and RAM.
It could help to detect problems and bugs too.
If Sergio could release 40x512 NNs,
(maybe with 7-men tb rescoring and also
trained with some Chess960 opening/games),
that would be simply awesome and blow away the competition.
Hai wrote: ↑Sun Dec 29, 2019 8:37 pm
Can we get some 40x512 nets?
That would also improve our understanding of NN development, NN training, GPU/CPU/NPU and RAM.
It could help to detect problems and bugs too.
If Sergio could release 40x512 NNs,
(maybe with 7-men tb rescoring and also
trained with some Chess960 opening/games),
that would be simply awesome and blow away the competition.
You will have to have a well scaling to 4 RTX 2080 Ti GPUs Lc0 engine and play very long time control games, for such a net to be better than some of the smaller nets. But it would be good in long analyses even on one RTX GPU.
Hai wrote: ↑Sun Dec 29, 2019 9:01 pm
Do you mean a smaller net, which has 5x or 10x more nodes per move, would get much more points than a 40x512 net?
I am not sure what are these 44 points and the statistical significance of the datapoints. Smaller net is not that bad in these fixed nodes plots, if one considers that it's 2-3 times faster, right?
In LTC games, probably some 2-3x more nodes per second on a strong RTX GPU than a 40bx512 HugeNet. So, maybe close to T60 nets or 30bx384 nets. But in 3-4 years I guess GPUs will get significantly stronger, and the HugeNet and even larger might become the strongest in Chess to LTC. Also nets with different structures might change optimal sizes.
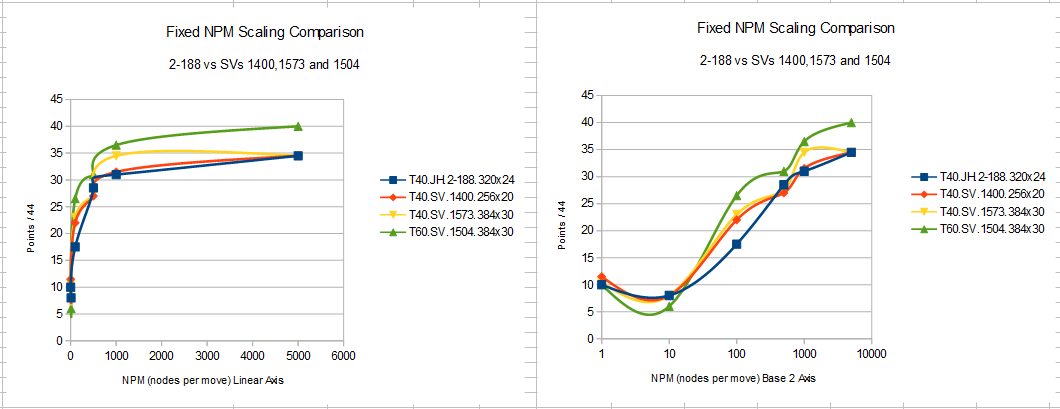
We have seen lots of scaling tests.
It means that LC0 Sergio 30x384, trained with T60 games, is already stronger with only 1000 nodes per move than the opponents with 10000 nodes per move.
Hai wrote: ↑Sun Dec 29, 2019 8:37 pm
Can we get some 40x512 nets?
That would also improve our understanding of NN development, NN training, GPU/CPU/NPU and RAM.
It could help to detect problems and bugs too.
If Sergio could release 40x512 NNs,
(maybe with 7-men tb rescoring and also
trained with some Chess960 opening/games),
that would be simply awesome and blow away the competition.
I think it would be fine. Regardless of what others say. The strongest NN at fast and slow time controls. Are the biggest and slowest NPS Neural Nets. In my testing. And that is tested in the real world against the other best engines. And tested on 1 RTX 2080ti. NPS is a very poor gauge on what is the best nets. You don't need 6 grand of graphic cards for them to top the charts.
So far 1 RTX has not yet reached it limits with the NN...
"The worst thing that can happen to a forum is a running wild attacking moderator(HGM) who is not corrected by the community." - Ed Schröder
But my words like silent raindrops fell. And echoed in the wells of silence.
Hai wrote: ↑Fri Jan 10, 2020 10:03 pm
We have seen lots of scaling tests.
It means that LC0 Sergio 30x384, trained with T60 games, is already stronger with only 1000 nodes per move than the opponents with 10000 nodes per move
It is pity but in fixed time/move tests (what models better the real competitions than the tests with fixed nodes)
jHorthos's J13B.2-188 (320x24 "mid" Net) is the better for more than one RTX 2080 Ti so far.
From Sergio's nets the bests are the 256x20-t40 (normal) Nets: 1400 and 1541. So for a single RTX card these are the best choices.