The answer is obvious for me: if using "stronger" evaluation parameters does not improve playing strength of a ~2600 Elo engine then the engine can't handle some positions reached by playing "stronger" moves. This is almost the same as with opening books: using a "3200 Elo" book does not always help a weak engine to play stronger, some positions will be reached that it can't handle. The reason can be anywhere: in the search as well as in the evaluation function itself. Unfortunately I do not have enough spare time to address that. Last time I actually worked on Jumbo was about 15-16 months ago. I plan to return at some point in time ...Desperado wrote: ↑Tue Jan 19, 2021 10:43 amI agree, that is another subject. The translation into elo is important and is measured completely different.
Well, it is not the fault of the tuner or the tuning algorithm itself if a smaller mse does not translate in better gameplay. At the same time i would always ask, why to hell do i get a lower mse that does not do that? Your goal should be to maximize the ratio when it helps and to close lacks as often as possible. The efficiency will rise then. imho.
Tapered Evaluation and MSE (Texel Tuning)
Moderator: Ras
-
Sven
- Posts: 4052
- Joined: Thu May 15, 2008 9:57 pm
- Location: Berlin, Germany
- Full name: Sven Schüle
Re: Tapered Evaluation and MSE (Texel Tuning)
Sven Schüle (engine author: Jumbo, KnockOut, Surprise)
-
Desperado

- Posts: 879
- Joined: Mon Dec 15, 2008 11:45 am
Re: Tapered Evaluation and MSE (Texel Tuning)
Well Sven, it must not be related to your engine. It can be also the data for example... It seems to be obvious, but it isn't. (I already updated my last post with a comment for HGM)Sven wrote: ↑Tue Jan 19, 2021 11:03 amThe answer is obvious for me: if using "stronger" evaluation parameters does not improve playing strength of a ~2600 Elo engine then the engine can't handle some positions reached by playing "stronger" moves. This is almost the same as with opening books: using a "3200 Elo" book does not always help a weak engine to play stronger, some positions will be reached that it can't handle. The reason can be anywhere: in the search as well as in the evaluation function itself. Unfortunately I do not have enough spare time to address that. Last time I actually worked on Jumbo was about 15-16 months ago. I plan to return at some point in time ...Desperado wrote: ↑Tue Jan 19, 2021 10:43 amI agree, that is another subject. The translation into elo is important and is measured completely different.
Well, it is not the fault of the tuner or the tuning algorithm itself if a smaller mse does not translate in better gameplay. At the same time i would always ask, why to hell do i get a lower mse that does not do that? Your goal should be to maximize the ratio when it helps and to close lacks as often as possible. The efficiency will rise then. imho.
-
hgm

- Posts: 28409
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Tapered Evaluation and MSE (Texel Tuning)
But it is exactly what Texel tuning is. Tuning by game results is an entirely different method. And I never claimed that Texel tuning was better then tuning through game play. Or in fact that Texel tuning was any good at all.
That obviously depends on the data set you use for tuning. There can be some hope that this correlates well if the test set is representative of what the engine will encounter in its search tree during game play. If that is not the case, all bets are of course off.And I have not seen any proof that "MSE(paramVector1) < MSE(paramVector2)" always implies "Elo(paramVector1) >= Elo(paramVector2)". Whether a parameter vector that results in a smaller MSE for a given data set really improves playing strength depends heavily on many properties of the engine.
What step size is satisfactory for the optimizing algorithm depends on the test set and on what and how many eval parameters you tune. So there is no guarantee that a step size used by the original author would also work for you. The proof would be whether you find the minimum MSE, and I would be surprised if the Texel author would have failed to find it. But you admitted on intentionally using a step size that fails to find the minimum MSE, thereby preventing true optimizations, and arrest it somewhere on the way. In my book that counts as sabotaging...Also I did not "sabotage the optimizer", that is another bullshit statement. I used the same algorithm and the same step size as the original author of Texel tuning.
-
Sven
- Posts: 4052
- Joined: Thu May 15, 2008 9:57 pm
- Location: Berlin, Germany
- Full name: Sven Schüle
Re: Tapered Evaluation and MSE (Texel Tuning)
I did not talk about "tuning through game play". Everyone who does parameter tuning plays games afterwards to control the impact of tuning on playing strength.
I did not expect a guarantee but nevertheless it worked.hgm wrote: ↑Tue Jan 19, 2021 12:49 pmWhat step size is satisfactory for the optimizing algorithm depends on the test set and on what and how many eval parameters you tune. So there is no guarantee that a step size used by the original author would also work for you.Also I did not "sabotage the optimizer", that is another bullshit statement. I used the same algorithm and the same step size as the original author of Texel tuning.
It is unlikely to find "the minimum MSE" with Texel tuning. The algorithm stops at a local minimum of the MSE, and there may be several of that kind. It seems you ignore this fact.
Funny wording. See my previous comment above: I did not "fail to find the minimum MSE". I did not "prevent true optimizations". I did not "arrest" anything. The tuning with the normal step size 1 converged to a local minimum and gave parameters that improved the engine significantly. Other tuning runs I performed back then (that was three years ago), including those with different step sizes, converged to other local minima and gave parameters that resulted in less strength improvement. That's all, end of the story.
Sven Schüle (engine author: Jumbo, KnockOut, Surprise)
-
Pio
- Posts: 338
- Joined: Sat Feb 25, 2012 10:42 pm
- Location: Stockholm
Re: Tapered Evaluation and MSE (Texel Tuning)
I am not so sure about that the test set should be as similar as possible to the nodes encountered by its search tree. Unbalanced positions are of course very helpful but positions where one side is leading by a huge amount will not be helpful since it is much more important for the engine to be able to make decisions where the score is even which is the case if you start out a game from the standard opening position.hgm wrote: ↑Tue Jan 19, 2021 12:49 pmBut it is exactly what Texel tuning is. Tuning by game results is an entirely different method. And I never claimed that Texel tuning was better then tuning through game play. Or in fact that Texel tuning was any good at all.
That obviously depends on the data set you use for tuning. There can be some hope that this correlates well if the test set is representative of what the engine will encounter in its search tree during game play. If that is not the case, all bets are of course off.And I have not seen any proof that "MSE(paramVector1) < MSE(paramVector2)" always implies "Elo(paramVector1) >= Elo(paramVector2)". Whether a parameter vector that results in a smaller MSE for a given data set really improves playing strength depends heavily on many properties of the engine.
What step size is satisfactory for the optimizing algorithm depends on the test set and on what and how many eval parameters you tune. So there is no guarantee that a step size used by the original author would also work for you. The proof would be whether you find the minimum MSE, and I would be surprised if the Texel author would have failed to find it. But you admitted on intentionally using a step size that fails to find the minimum MSE, thereby preventing true optimizations, and arrest it somewhere on the way. In my book that counts as sabotaging...Also I did not "sabotage the optimizer", that is another bullshit statement. I used the same algorithm and the same step size as the original author of Texel tuning.
I firmly believe that training on positions close to the end or weighing positions more closer to the end will make Texels algorithm better. I also believe that it might be interesting to minimise the absolute error instead of the squared error and the reason is simple. It should be equally good/bad to make one -4 % bad decision as doing four 1 % good decisions. Of course the search might win by not doing any really big bad decisions but if you want the best evaluation without regard of search, you should minimise the absolute error.
One problem with Texels algorithm is that it assumes a sigmoid function between centipawns and win probability. This might not be true and even if it is a good approximation it might not be true for different parts of the game. I guess that the tunings would have lead to different results if you would have assumed that each phase would have a separate K value and after determining the different K values you would use them while minimising the errors. If anyone would try this it should give some gains. It is not obvious to me that the K value will remain the same after the optimisation because you don’t know if the new parameters have changed the shape of the curve.
-
hgm
- Posts: 28409
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Tapered Evaluation and MSE (Texel Tuning)
Not really. The most important by far is that the engine will recognize the positions were one side is leading by a huge amount, and can then correctly identify who is leading. And valuing a Queen like 1.5 Pawn will not do much for recognizing totally won positions.Pio wrote: ↑Wed Jan 20, 2021 12:51 amI am not so sure about that the test set should be as similar as possible to the nodes encountered by its search tree. Unbalanced positions are of course very helpful but positions where one side is leading by a huge amount will not be helpful since it is much more important for the engine to be able to make decisions where the score is even which is the case if you start out a game from the standard opening position.
The following image sketches the problem:
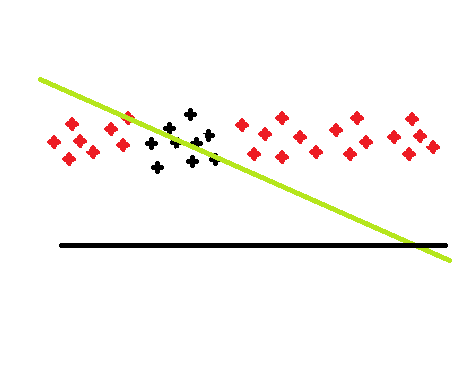
The line that best fits the data points in some narrow range (the black points) will adapt its slope to get a marginally better prediction of the accidental vertical scatter. That line is no good for predicting the red points, though. For points sufficiently far from the region on which it was based, it doesn't even get the sign right. So the attempt to get a marginally better discrimination within the black range leads to total disaster in the wings. If you would have taken the red points into account during the fitting, you would have gotten a practical horizontal line, which does a good job everywhere, and is only marginally worse in the black area.
You see that happening here: piece values become non-sensical. This leads to huge mispredictions of heavilay won or lost positions that were left out of the test set, and gives you an engine that strives for forcing losing trades.
-
Pio
- Posts: 338
- Joined: Sat Feb 25, 2012 10:42 pm
- Location: Stockholm
Re: Tapered Evaluation and MSE (Texel Tuning)
I understand your point but making huge mispredictions might not be as bad as you think with an engine. What is really important for an alpha beta search is to judge which positions are better than others from a set of positions close to each other. Of course when you search very deep, positions will become more and more different and it will be more important to judge very different positions.hgm wrote: ↑Wed Jan 20, 2021 12:15 pmNot really. The most important by far is that the engine will recognize the positions were one side is leading by a huge amount, and can then correctly identify who is leading. And valuing a Queen like 1.5 Pawn will not do much for recognizing totally won positions.Pio wrote: ↑Wed Jan 20, 2021 12:51 amI am not so sure about that the test set should be as similar as possible to the nodes encountered by its search tree. Unbalanced positions are of course very helpful but positions where one side is leading by a huge amount will not be helpful since it is much more important for the engine to be able to make decisions where the score is even which is the case if you start out a game from the standard opening position.
The following image sketches the problem:
The line that best fits the data points in some narrow range (the black points) will adapt its slope to get a marginally better prediction of the accidental vertical scatter. That line is no good for predicting the red points, though. For points sufficiently far from the region on which it was based, it doesn't even get the sign right. So the attempt to get a marginally better discrimination within the black range leads to total disaster in the wings. If you would have taken the red points into account during the fitting, you would have gotten a practical horizontal line, which does a good job everywhere, and is only marginally worse in the black area.
You see that happening here: piece values become non-sensical. This leads to huge mispredictions of heavilay won or lost positions that were left out of the test set, and gives you an engine that strives for forcing losing trades.
I think that if Sven or Desperado would determine different K values for the different phases, they wouldn’t get their strange results.
Minimising the absolute error instead of squared error will make the tuning more robust to labelling errors and will make the evaluation prediction better but might make the search worse, but I really don’t know.
Also putting more weight to the end will automatically make the positions more unbalanced since usually wins comes from unbalanced positions and draws from more balanced positions.
-
Desperado
- Posts: 879
- Joined: Mon Dec 15, 2008 11:45 am
Re: Tapered Evaluation and MSE (Texel Tuning)
Hello Pio,Pio wrote: ↑Wed Jan 20, 2021 12:37 pmI understand your point but making huge mispredictions might not be as bad as you think with an engine. What is really important for an alpha beta search is to judge which positions are better than others from a set of positions close to each other. Of course when you search very deep, positions will become more and more different and it will be more important to judge very different positions.hgm wrote: ↑Wed Jan 20, 2021 12:15 pmNot really. The most important by far is that the engine will recognize the positions were one side is leading by a huge amount, and can then correctly identify who is leading. And valuing a Queen like 1.5 Pawn will not do much for recognizing totally won positions.Pio wrote: ↑Wed Jan 20, 2021 12:51 amI am not so sure about that the test set should be as similar as possible to the nodes encountered by its search tree. Unbalanced positions are of course very helpful but positions where one side is leading by a huge amount will not be helpful since it is much more important for the engine to be able to make decisions where the score is even which is the case if you start out a game from the standard opening position.
The following image sketches the problem:
The line that best fits the data points in some narrow range (the black points) will adapt its slope to get a marginally better prediction of the accidental vertical scatter. That line is no good for predicting the red points, though. For points sufficiently far from the region on which it was based, it doesn't even get the sign right. So the attempt to get a marginally better discrimination within the black range leads to total disaster in the wings. If you would have taken the red points into account during the fitting, you would have gotten a practical horizontal line, which does a good job everywhere, and is only marginally worse in the black area.
You see that happening here: piece values become non-sensical. This leads to huge mispredictions of heavilay won or lost positions that were left out of the test set, and gives you an engine that strives for forcing losing trades.
I think that if Sven or Desperado would determine different K values for the different phases, they wouldn’t get their strange results.
Minimising the absolute error instead of squared error will make the tuning more robust to labelling errors and will make the evaluation prediction better but might make the search worse, but I really don’t know.
Also putting more weight to the end will automatically make the positions more unbalanced since usually wins comes from unbalanced positions and draws from more balanced positions.
i need to be more detailed at another time. But of course i played around with the loss function and of course i used different K Values.
Some have been reported with some setups and measurements. Conclusion, it keeps to be the data. (It keeps to be like that when i do not restrict the tuner in a way, that it stops early although there might be another mse. Another observation was that the result
became better when using stable(some kind of quiet) positions and full evaluation. It was observable that the pawn value got normal,
and the tuner was able to map the imbalance into other evaluation paramters)
I do not have the numbers at hand for quiet-labeled.epd, but you pointed out for several times that you would use positions more related to an endgame phase. I agree with you that the correlation between the position properties and the result gets stronger. The idea is not bad at all, but i have some
different thoughts on that too. The known quiet-labeled.epd, if i remember correctly, meets the requirements more than the data that was discussed in this thread. I will come back to this topic but in the other thread about training data. Maybe tomorrow.
@HG
I never realized that the people talk about another essential part of the data. The result of a game is strongly influenced by the chess playing
entity. There should be some kind of independency of that fact. We can easily build a database where 3000 elo engines play with handicap against 2000 Elo engines and we would learn that playing with a queen less or a rook less the winning probability will rise
Currently i build my own tuning algorithm that will address some intersting topics on that (at least for me).
I report later in the other thread. Maybe tomorrow too.
-
hgm
- Posts: 28409
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
-
Pio
- Posts: 338
- Joined: Sat Feb 25, 2012 10:42 pm
- Location: Stockholm
Re: Tapered Evaluation and MSE (Texel Tuning)
What I meant using many K values was that you determine as many K values as you have phases so you will have to determine 24 K values each corresponding to one phase. In that way you will have a good mapping between centipawn values and win probabilities for each phase. As it is now you and everyone else makes the assumption that you have the same centipawn to probability mapping for each phase. When you have determined each K value for each phase you will use the K value that corresponds to the position’s phase while minimising the error. So when you sum up the errors over your entire dataset you will use all 24 different K values.Desperado wrote: ↑Wed Jan 20, 2021 1:26 pmHello Pio,Pio wrote: ↑Wed Jan 20, 2021 12:37 pmI understand your point but making huge mispredictions might not be as bad as you think with an engine. What is really important for an alpha beta search is to judge which positions are better than others from a set of positions close to each other. Of course when you search very deep, positions will become more and more different and it will be more important to judge very different positions.hgm wrote: ↑Wed Jan 20, 2021 12:15 pmNot really. The most important by far is that the engine will recognize the positions were one side is leading by a huge amount, and can then correctly identify who is leading. And valuing a Queen like 1.5 Pawn will not do much for recognizing totally won positions.Pio wrote: ↑Wed Jan 20, 2021 12:51 amI am not so sure about that the test set should be as similar as possible to the nodes encountered by its search tree. Unbalanced positions are of course very helpful but positions where one side is leading by a huge amount will not be helpful since it is much more important for the engine to be able to make decisions where the score is even which is the case if you start out a game from the standard opening position.
The following image sketches the problem:
The line that best fits the data points in some narrow range (the black points) will adapt its slope to get a marginally better prediction of the accidental vertical scatter. That line is no good for predicting the red points, though. For points sufficiently far from the region on which it was based, it doesn't even get the sign right. So the attempt to get a marginally better discrimination within the black range leads to total disaster in the wings. If you would have taken the red points into account during the fitting, you would have gotten a practical horizontal line, which does a good job everywhere, and is only marginally worse in the black area.
You see that happening here: piece values become non-sensical. This leads to huge mispredictions of heavilay won or lost positions that were left out of the test set, and gives you an engine that strives for forcing losing trades.
I think that if Sven or Desperado would determine different K values for the different phases, they wouldn’t get their strange results.
Minimising the absolute error instead of squared error will make the tuning more robust to labelling errors and will make the evaluation prediction better but might make the search worse, but I really don’t know.
Also putting more weight to the end will automatically make the positions more unbalanced since usually wins comes from unbalanced positions and draws from more balanced positions.
i need to be more detailed at another time. But of course i played around with the loss function and of course i used different K Values.
Some have been reported with some setups and measurements. Conclusion, it keeps to be the data. (It keeps to be like that when i do not restrict the tuner in a way, that it stops early although there might be another mse. Another observation was that the result
became better when using stable(some kind of quiet) positions and full evaluation. It was observable that the pawn value got normal,
and the tuner was able to map the imbalance into other evaluation paramters)
I do not have the numbers at hand for quiet-labeled.epd, but you pointed out for several times that you would use positions more related to an endgame phase. I agree with you that the correlation between the position properties and the result gets stronger. The idea is not bad at all, but i have some
different thoughts on that too. The known quiet-labeled.epd, if i remember correctly, meets the requirements more than the data that was discussed in this thread. I will come back to this topic but in the other thread about training data. Maybe tomorrow.
@HG
I never realized that the people talk about another essential part of the data. The result of a game is strongly influenced by the chess playing
entity. There should be some kind of independency of that fact. We can easily build a database where 3000 elo engines play with handicap against 2000 Elo engines and we would learn that playing with a queen less or a rook less the winning probability will rise
.
Currently i build my own tuning algorithm that will address some intersting topics on that (at least for me).
I report later in the other thread. Maybe tomorrow too.