Is it actually weaker though?
https://images.anandtech.com/graphs/gra ... 119343.png
{kind=link}
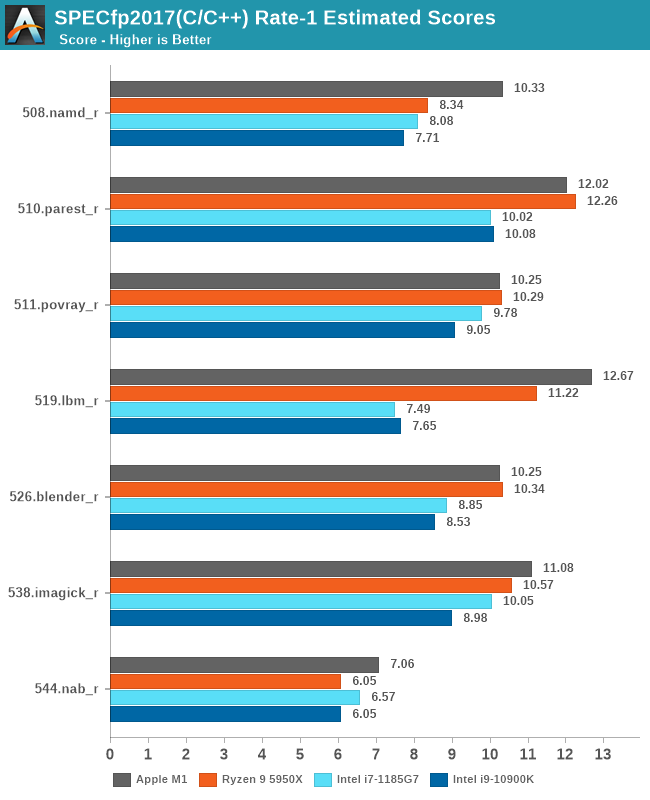
Floating point performance on the M1 is best of class.
Moderator: Ras
Is it actually weaker though?
That's totally irrelevant though! The width of the vector instructions doesn't determine the performance. In fact, if you could choose you would choose size=1 or 32-bit vectors because it is more flexible. It's the amount of instructions you can execute at once and their/latency throughput. You could have 512-bit vectors and take 5 times as long to process them, you will just run slower. (This was the case on AMD Bulldozer for AVX code, and Zen 1 had a similar throughput disadvantage compared to Haswell and later).BetaPro wrote: ↑Wed Feb 10, 2021 2:38 pm If you look at George's benchmark, M1 dropped way more performace going from classical to NNUE than Intel. So, good vector instructions seem more important than floating point performance. ARM Neon is only 128 bits compared to at least 256 bits in x86 AVX stuff, that's probably why ARM is slower for NNUE.
Wait, the floating point tests in SPEC, how many of them actually use vector instructions? I thought most of them don't actually use it. If they do, then M1 indeed has good SIMD performance, the performance loss must have come from somewhere else, could be worth doing more optimization.Gian-Carlo Pascutto wrote: ↑Wed Feb 10, 2021 3:10 pmThat's totally irrelevant though! The width of the vector instructions doesn't determine the performance. In fact, if you could choose you would choose size=1 or 32-bit vectors because it is more flexible. It's the amount of instructions you can execute at once and their/latency throughput. You could have 512-bit vectors and take 5 times as long to process them, you will just run slower. (This was the case on AMD Bulldozer for AVX code, and Zen 1 had a similar throughput disadvantage compared to Haswell and later).BetaPro wrote: ↑Wed Feb 10, 2021 2:38 pm If you look at George's benchmark, M1 dropped way more performace going from classical to NNUE than Intel. So, good vector instructions seem more important than floating point performance. ARM Neon is only 128 bits compared to at least 256 bits in x86 AVX stuff, that's probably why ARM is slower for NNUE.
M1 seems to have 4 full 128-bit NEON pipelines, compared to the 4 full 256-bit AVX2 pipelines in Zen2+ and Haswell+.
So it sounds as if Zen2 has twice the throughput, BUT, of those 4 pipelines, all 4 of them can do a multiply-add in the same cycle on the M1, whereas Zen2 can only do 2. That's the why M1 looks so competitive in the floating point tests, instead of running at half the speed. (Also remember Zen3 can run at 5GHz single core, while the M1 is "only" 3.2GHz, yet it's still performing better in the test I linked!)
But as to why it is a bit slower on the Stockfish NNUE code, probably requires diving more deeply into the details. The relevant code might just not be as well optimized yet either.
SPEC is pure C/C++/Fortran source code - it needs to be 100% portable and machine independent - but modern compilers have no problem vectorizing appropriately written code. I don't know how much this applies to SPECint2017, but I know that for SPECint2006 the Intel C compiler even vectorized this loop:
The eval in chess engines tends to be pure integer, I think even NNUE uses mostly 16-bit integers? For Leela it is a bit more complicated, but the version in SPEC is the MCTS engine, so there's no neural network evaluation and runtime is indeed dominated by integer performance.In SPECInt, Sjeng and Leela are all written by you, right? I thought in chess, even though eval are done in fp, they aren't a big part of the performance numbers, that's why they are all in SPECInt instead of SPECfp, right?

Hi Giancarlo,Gian-Carlo Pascutto wrote: ↑Tue Feb 09, 2021 9:56 pm Performance of Stockfish dev from today looks like:
This is on an M1 Air. I love the fact that it's 100% fanless.Code: Select all
Zen1 1700X 3.2GHz: 1520000 Ivy Bridge 3.5GHz: 1760000 Haswell 3.4GHz: 1860000 M1 3.2GHz: 2390000 Zen2 3900X 3.8-4.2GHz: 2490000
Hi!syzygy wrote: ↑Wed Dec 09, 2020 12:27 pmOr I just spend my time wisely. My intention here was just to point out the in my view unwarranted negativity. It reminds me of the initial reception in this forum of Alpha Chess Zero (and many here will probably still deny that LC0 wouldn't have existed without Deepmind's papers).
No, the M1 is just that good, regardless of the brand on it. The 4900H you compare is a 45W chip (still slower for single core tasks!), and the RTX 2060 (mobile) is a 60-ish W card. The M1 is ~15W, total. You might appreciate the difference if you try to put both machines on your lap while using them.twobeer wrote: ↑Wed Feb 10, 2021 7:39 pm In the similar price range one could just get a Asus TUF Gaming A15 with AMD Ryzen 9 4900H and NVIDIA GeForce RTX 2060 that runs ALL chess programs much better than an inflexible locked down "appliance-books" from Apple.
I am truly surprised people still throw money at "brand"-recognition (They buy Computers in the same mental mind-set as buying fashion), hype over quality, performance, flexibility and price/value ....