Oh boy... Haha. How did I miss that?
Sorry
Moderator: Ras
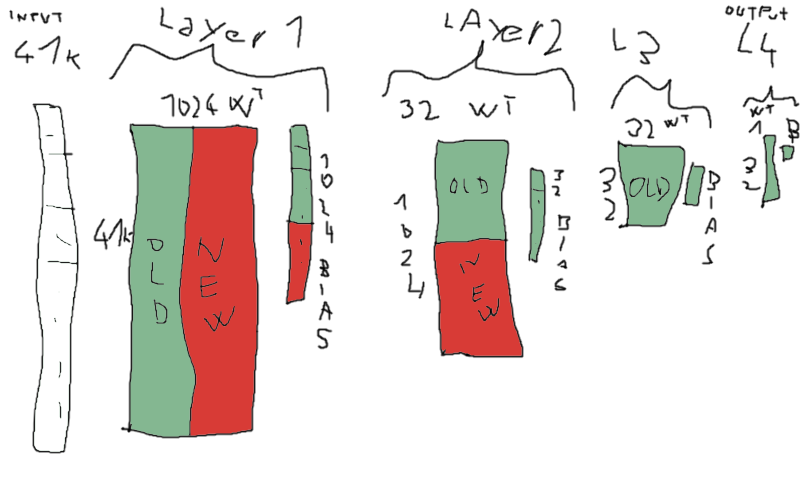
Cool! We like diagrams.mar wrote: ↑Mon Mar 01, 2021 3:10 am this is how I imagine Chris's idea, I hope I got the numbers right:
indeed, it can be viewed simply as matrix-vector multiplication which is nothing but a series of dot products
I like to imagine transposed weight matrix, biases could be encoded as part of the weight matrix with implied corresponding input set to 1
(red parts are new weights)
so basically you create a temp buffer and initialize with biases, then multiply the weights with corresponding input and sum (=fma). if spills can be avoided, it's actually quite easy for modern compilers to vectorize this, but that's not the point
I've tried it on a much smaller net (MNIST - unrelated to chess) and it works, however I use a stochastic approach, not backpropagation.
and it works, but I have the feeling that the trainer has a hard time to actually improve, despite the fact that the 1st hidden layer contains
twice the amount of weights. probably more "epochs" is needed.
the larger net is 784-256-64-10 but it seems I'm already beating (test set accuracy 97.16% = 2.84% error) the results of a 784-500-150-10 net mentioned here: http://yann.lecun.com/exdb/mnist/, my best 784-128-64-10 had 96.88% test set accuracy already.
note that I use leaky ReLU (x<0 => epsilon*x else x), haven't compared to max(x, 0) yet so no idea if it's actually beneficial at all
the problem is that this 2x bigger net will have 2x slower inference, so it has to pay for itself in terms of performance.
not sure if Chris's approach is viable, but might be worth trying. In fact, why double and not try something like 3/2, but I'm sure SF devs tried
many other topologies and they know what worked best for them.

sure, but let's not forget that you make the evaluation 2x slower, not the engine overall. question is how much time does NNUE eval actually consume, but it's certainly less than 100% overall, so the slowdown will be less than 2x
Well, exactly, why double the first layer and double the computation time? Seems quite an odd design choice for someone under pressure to come up with a new commercial net on a par with, or improving on SF-NNUE. Which is why I wondered, given the fibbing about much else, if it was a design choice which enabled building on existing performance of SF-NNUE by hidden incorporation of its existing weights.
yes, I believe it would be more interesting to investigate going in the opposite direction and try to build smaller nets and focus on topology/features to see if you can build something on par with NNUE - as a bonus you'd get faster inference and faster training.hgm wrote: ↑Mon Mar 01, 2021 11:15 am Why the emphasis on the width of the first hidden layer, btw? It already is the widest layer by far. Why not double the second hidden layer to 64? Or add an extra layer of 32? Or change the topology to include 'skip connections' between more distant layers? Or re-examine the king-piece concept, and repurpose some of the first-layer weights to become (say) pawn-piece tables?
The king-piece concept might be great for learning about King-Safety, but it is ill-suited for many other types of chess knowledge, and can only store that inefficiently. Rather than combatting that inefficiency by just making it very large, it sems better to make it smarter.
it’s theoretically clear however. All that’s required is to train at low LR, avoiding regressing. The objective isn’t to “get better”, although that would be nice, it’s to stay the same, whilst appearing to be different.hgm wrote: ↑Mon Mar 01, 2021 11:51 am But you would also be able to do that when doubling the width of the second layer. For every new cell you add anywhere you can take random weights on the output connections and zero weights on the input connections. To make sure they initially do not alter the network output (for lack of input), and that they are not permanently dead. If you want to slip in an extra layer you can use a layer of weights that is all zeros, except for the connection between 'corresponding' cells, which you give weight 1.
BTW, it is by no means proven that this way of expanding on an existing net would be any easier than training it from scretch.
The fact that you crammed all thr knowledge of the original learning effort int a smaller net might have led to some over-simplification of that knowledge, which might be hard to eradicate. (Since even the simplified knowledge contributes something, so that the reward for replacing it by more accurate knowledge is lower.)