Thoughts on "Zero" training of NNUEs
Moderator: Ras
-
towforce

- Posts: 13095
- Joined: Thu Mar 09, 2006 12:57 am
- Location: Birmingham UK
- Full name: Graham Laight
Re: Thoughts on "Zero" training of NNUEs
All this talk about determining what the weights will represent looks like the opposite of what this thread is asking about: the system working out what's important all by itself.
Human chess is partly about tactics and strategy, but mostly about memory
-
hgm

- Posts: 28505
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Thoughts on "Zero" training of NNUEs
True. But in the conventional implementation of NNUE the programmer did already decide that it is the relative positioning of pieces w.r.t. the King that is the dominant issue, rather than having the system work that out for itself. (For no other reason that this happened to be the dominant feature in Shogi!)
If you really want the system to work out everything for itself, you should start from a more symmetric input layer, which considers every pair of piece types equally important. In Chess there are 12 (colored) piece types, so you would have 12x11/2 = 66 inhomogeneous pairs, and 8 homogeneous pairs. (Forget about double Queens...) So 74 in total. And then you want to provide a number of weights for each type pair. (Like the traditional approach provides 256 KPST tables.)
The problem is that NNUE is only really 'easily updatable' when you move a piece that is not in many pairs. In the traditional approach these are only the non-roya pieces; these are paired with white and black Kings. The Kings are paired with all other pieces, though. So if you move these, the first layer has to be recalculated completely. Fortunately King moves are rather rare in the tree. Pawn moves would also be rare, as Pawns are even less mobile than Kings (but there are more of them...). For other types it might become expensive.
Of course this could be compensated by the number of weights you use for each pair. If you have 256 KPST tables, moving a non-royal would still have to add the 256 scores for the new locations, and subtract those from the old locations for the incremental update. Basically you have a 32x32 matrix of piece pairs, and when a piece of a given piece moves, you have to update the pair scores in the rows and columns for it (using only the part above the diagonal because of symmetry). With traditional KPST only the cells of the King rows contain 256 weights, the rest contain none. So moves of non-royal pieces require 2x256 updates (as there is nothing in its row, and it intersects two King rows). A King has 256 weights in all the cells in its row, and its move would require very many updates. (So many, in fact, that recalculation from scratch is twice as cheap.)
If you would spread out the weights more evenly over type pairs, e.g. use 16 tables per piece pair, each piece move have to update the score from 32x16 = 512 tables, as usual. (In fact 16 less, as there is no 'self-interaction'.) And King moves would be as cheap as any other. As the board empties the number of required updates would go down.
If you really want the system to work out everything for itself, you should start from a more symmetric input layer, which considers every pair of piece types equally important. In Chess there are 12 (colored) piece types, so you would have 12x11/2 = 66 inhomogeneous pairs, and 8 homogeneous pairs. (Forget about double Queens...) So 74 in total. And then you want to provide a number of weights for each type pair. (Like the traditional approach provides 256 KPST tables.)
The problem is that NNUE is only really 'easily updatable' when you move a piece that is not in many pairs. In the traditional approach these are only the non-roya pieces; these are paired with white and black Kings. The Kings are paired with all other pieces, though. So if you move these, the first layer has to be recalculated completely. Fortunately King moves are rather rare in the tree. Pawn moves would also be rare, as Pawns are even less mobile than Kings (but there are more of them...). For other types it might become expensive.
Of course this could be compensated by the number of weights you use for each pair. If you have 256 KPST tables, moving a non-royal would still have to add the 256 scores for the new locations, and subtract those from the old locations for the incremental update. Basically you have a 32x32 matrix of piece pairs, and when a piece of a given piece moves, you have to update the pair scores in the rows and columns for it (using only the part above the diagonal because of symmetry). With traditional KPST only the cells of the King rows contain 256 weights, the rest contain none. So moves of non-royal pieces require 2x256 updates (as there is nothing in its row, and it intersects two King rows). A King has 256 weights in all the cells in its row, and its move would require very many updates. (So many, in fact, that recalculation from scratch is twice as cheap.)
If you would spread out the weights more evenly over type pairs, e.g. use 16 tables per piece pair, each piece move have to update the score from 32x16 = 512 tables, as usual. (In fact 16 less, as there is no 'self-interaction'.) And King moves would be as cheap as any other. As the board empties the number of required updates would go down.
-
Engin
- Posts: 1001
- Joined: Mon Jan 05, 2009 7:40 pm
- Location: Germany
- Full name: Engin Üstün
Re: Thoughts on "Zero" training of NNUEs
That is my interesting point too, just need for the first a very simple network with 12x64 inputs and then just only with 32x32 hidden and only one output layer, then teaching that with only the outcome/result of a game (not about centipawns) to let it find out by self why the game has ended with a win/lose or draw. so i get then a winning percentage of a game, other problem is then to backcalculate the winning percentage to centipawn represantation output from a floating point for the search.
Not having 5000 TPUs to work with, I feel that at least two things are essential:
- As simple a network as possble (768->(32x2)->1 ???)
- Higher quality labels, even working with just 0, 0.5, and 1
Does anybody know how ist formula of winning percentage WDL to centipawn and also back again is ?
other question is why the neural network are solve like mnist or iris problem quickly but for chess to solve so much longer and why it need so much data for to solve it. Bigger neural network solves chess not faster i guess too.
actually the training process with GPU is not faster then with CPU, why ?
-
johnhamlen65

- Posts: 31
- Joined: Fri May 12, 2023 10:15 am
- Location: Melton Mowbray, England
- Full name: John Hamlen
Re: Thoughts on "Zero" training of NNUEs
Hi Engin,Engin wrote: ↑Thu Oct 31, 2024 7:44 pm Hi John,
to understanding NNUE is very hard, i am my self did not even understand them all how can be so large inputs 2x10x64x64 (= 81920) ->2x256->32->32->1 can fast working for the AB search algorithm, yes i know about SIMD, but get not really the speed what i am try to do something different with my own neural network with smaller size of networks like 2x768 for each side an then just only 2x8 to 1 output, the network take a lot of time to learn something, well bigger sizes including the king square drops down a lot. i got a little bit speedup of x10 with OpenMP SIMD for the forward function now, let's see.
Of course you can get a lot more speed with quantize the model from floating point to integer later after the training prozess like the NNUE are doing. Training with integer's are not possible :/
Great meeting you and playing Tornado in Spain.
"Understanding NNUE is very hard" - Well I can't agree with you more on that one!
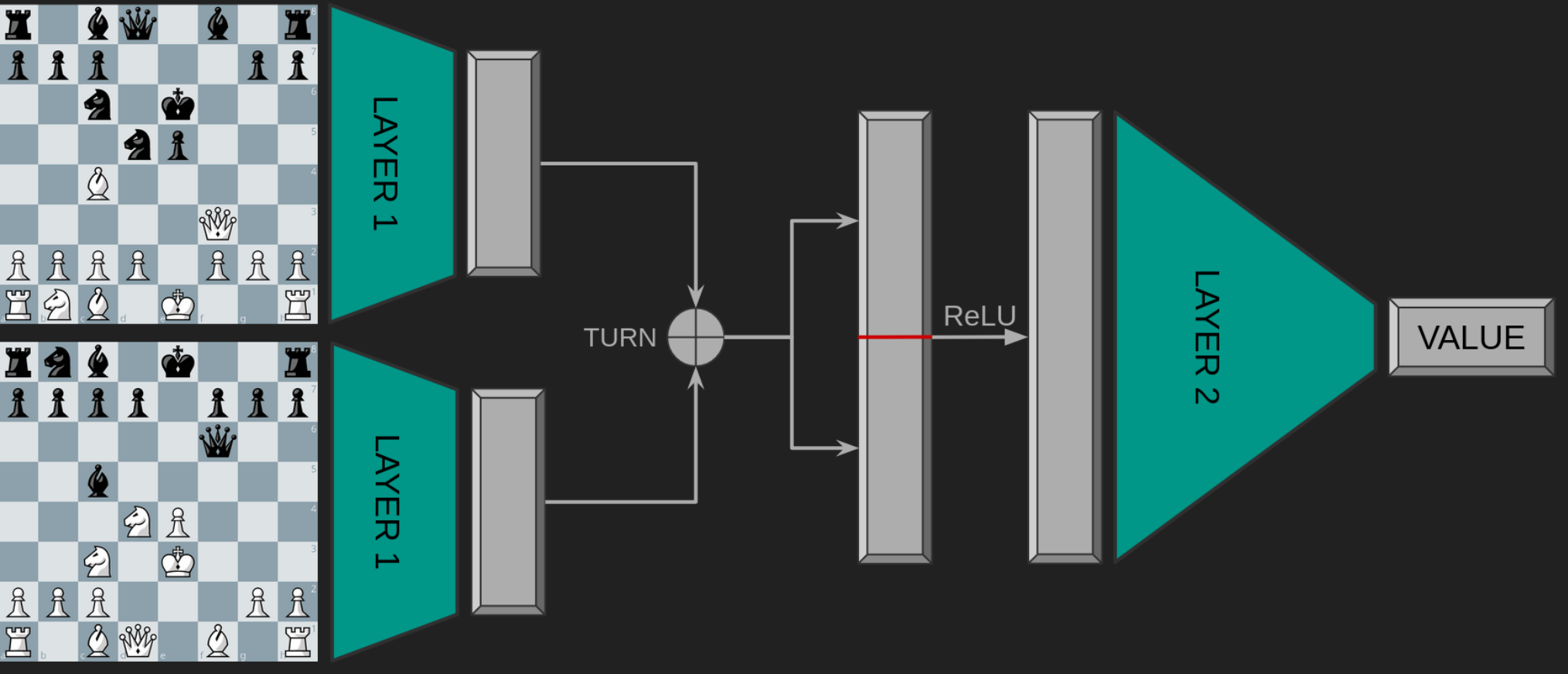
For instance: I (sort of!) understand why the inputs of the Stockfish NNUE are split into two, because the two halves describe how all the peices on the board relate to 1) the king of the side to move, and 2) the king of the side not to move.
However, if we have 2 x 768, how would the two halves differ? The 768 bits fully describe the position on the board. I could understand 2 x 384 inputs, one for the pieces of side to move, and one for the side not to move.
Or have I got completely the wrong end of the stick? (Almost certainly
Many thanks,
John
-
johnhamlen65
- Posts: 31
- Joined: Fri May 12, 2023 10:15 am
- Location: Melton Mowbray, England
- Full name: John Hamlen
Re: Thoughts on "Zero" training of NNUEs
Thanks for all the links and pointers David!David Carteau wrote: ↑Fri Nov 01, 2024 9:45 amHello John,johnhamlen65 wrote: ↑Thu Oct 31, 2024 6:22 pm I'm fascinated by David Carteau's memberlist.php?mode=viewprofile&u=7470 experiments and positive results with Orion https://www.orionchess.com/, but would love some thoughts and advice on how I can best approach this.
I'm glad that some people are interested in my experiments! I was myself fascinated by reading the blogs of Jonatan Pettersson (Mediocre) and Thomas Petzke (iCE) a few years ago, and these two guys made me want to develop my own chess engine
I would say that you can start with a simple network like 2x(768x128)x1: it will give you a decent result and a great speed.
But be aware that there's always a trade-off between speed and accuracy: bigger networks will improve accuracy and reduce speed, but at the same time the search will take advantage of this accuracy and you'll be able to prune more reliably, for example.
Point of attention: in my experiments, networks with two perspectives always gave me better results (and training stability), i.e. prefer 2x(768x128)x1 to 768x256x1 (maybe someone else could share its thoughts on that).
Yes, that's the big difficulty: how to turn such "poor" labels (game results) into valuable information to train a strong networkjohnhamlen65 wrote: ↑Thu Oct 31, 2024 6:22 pm Has anyone considered "tapering" the contributions of the training positions so more weight is given to positions near the end of the game
Connor McMonigle (Seer author) had a really clever idea about this (it's not really "tapering", but the idea remains to start from endgame positions, where labels are more reliable)!
David
I'm keen to get started on experimenting with training a (very) simple once of go my head around things. At the moment I'm still a bit confused about things as basic as how the 2 halves of a 2 x 768 input layer would differ (see my answer to Engin). So maybe I've got rather a long way to go before being "productive"!
Thanks for pointing me towards Connor's Seer ideas. I know we're a long way from solving chess - (good!!) - but it reminds me of what Chinook was doing for checkers.
All the best,
John
-
johnhamlen65
- Posts: 31
- Joined: Fri May 12, 2023 10:15 am
- Location: Melton Mowbray, England
- Full name: John Hamlen
Re: Thoughts on "Zero" training of NNUEs
Thanks HG,hgm wrote: ↑Fri Nov 01, 2024 11:33 am I would expect to get better performance from networks of the same size when you adapt the network better to the type of information that we know is important in Chess. The networks that are now popular use king-piece-square tables, which is very good for determining king safety. Which in Shogi, from which the NNUE idea was copied, of course is the overwhelmingly dominant evaluation term.
In chess King Safety is also important, but Pawn structure might be even more important. With only king-piece-square inputs in the first layer recognizing other piece relations (e.g. passers) must be done indirectly, by the deeper layers of the network. Which puts a heavier burden there, and thus probably needs a larger network to perform it.
So it might be worth it to also include some tables that depend on the relation between Pawns and other pieces, and Pawns w.r.t. each other. Like Kings, Pawns are not very mobile either. So when some of the tables are pawn-piece-square rather than king-piece-square, most moves would still only have to update the input they provide to the next layer by accounting for the moved piece, rather than having to recalculate everything because the Pawn moved.
"Pawns are the soul of chess" - Philidor
... so I love this idea. The trick will be how to do it efficiently. I wrote a quick script to count the number of moves of each type of piece in a million Lichess games (https://database.lichess.org/ July 2014). King moves were 12.9%, whilst pawn moves were 28.4% of all moves. So not too bad there, but there are 8 different pawns rather than 1 king. I guess we could use the idea of "chunking" pawn positions, but this gets further away from a "zero" approach.
All the best
John
-
johnhamlen65
- Posts: 31
- Joined: Fri May 12, 2023 10:15 am
- Location: Melton Mowbray, England
- Full name: John Hamlen
Re: Thoughts on "Zero" training of NNUEs
Thanks Charles. Great meeting you and Lisa too.CRoberson wrote: ↑Fri Nov 01, 2024 3:55 pm Hi John,
Great meeting you and Carol in Spain! You are on the right track with that idea. There are papers written on TDL (Temporal Difference Learning) from the late 1980s and early 1990s. The ones to read are by Gerald Tessauro of the IBM Thomas J. Watson research center on Backgammon. He has papers on using neural nets in the normal fashion and on TDL. TDL was better. The idea is based on the fact that in at least long games the likelyhood that the first several moves are the problem is far smaller than a move(s) closer to the end of the game.
Regards,
Charles
Good call re: the Tessauro TDL work. The random rollouts also have a lot of overlap with the "zero" training approach for chess. https://www.bkgm.com/articles/tesauro/tdl.html
All the best, John
-
johnhamlen65
- Posts: 31
- Joined: Fri May 12, 2023 10:15 am
- Location: Melton Mowbray, England
- Full name: John Hamlen
Re: Thoughts on "Zero" training of NNUEs
Hi Engin,
You can reverse the Lichess Accuracy Metric to get this:
centipawns = log((2 / ((win_probability - 0.5) * 2 + 1)) - 1) / -0.00368208
Hope this helps,
John
-
op12no2
- Posts: 560
- Joined: Tue Feb 04, 2014 12:25 pm
- Location: Gower, Wales
- Full name: Colin Jenkins
Re: Thoughts on "Zero" training of NNUEs
I'm still on a single accumulator myself, but I asked about this on Discord recently and you can use a second perspective - flip board, swap colour - attached to a second accumulator and then feed both (concatenated) accumulators into the single output (or more layers). The weights for the second perspective can be flipped weights from the first or you can train both perspectives.johnhamlen65 wrote: ↑Tue Nov 05, 2024 8:32 am However, if we have 2 x 768, how would the two halves differ? The 768 bits fully describe the position on the board. I could understand 2 x 384 inputs, one for the pieces of side to move, and one for the side not to move.
Apparently this document is a bit out of date WRT the coal face but it's still packed with useful info:-
https://github.com/official-stockfish/n ... cs/nnue.md
-
op12no2
- Posts: 560
- Joined: Tue Feb 04, 2014 12:25 pm
- Location: Gower, Wales
- Full name: Colin Jenkins